FM
线性模型
设有$d$个特征,记为:$\pmb{X} = [x_1, x_2, … , x_d]$,则线性模型的表达式为:
$$
p = b + \sum_{i=1}^d w_i · x_i
$$
其中,$b$为偏置,总共$d+1$个模型参数。$p$是预测结果,也就是特征和权重参数的加权和。因为没有乘法操作,所以特征之间没有交叉。
线性模型+二阶交叉
$$
p = b + \sum_{i=1}^d w_i · x_i + \sum_{i=1}^d \sum_{j=i+1}^d u_{ij} · x_i · x_j
$$
其中,$w_i$是为每个特征分配一个权重参数,而$u_{ij}$则是为每一组交叉特征分配一个权重参数,那么其参数量则为$O(d^2)$。若特征比较多,则参数量会非常多。
优化思路:把$u_{ij}$这个方阵近似用两个向量内积表示,即$\pmb{U} ≈ \pmb{V} · \pmb{V^T}$。参数量从$O(d^2) \rightarrow O(kd)$。
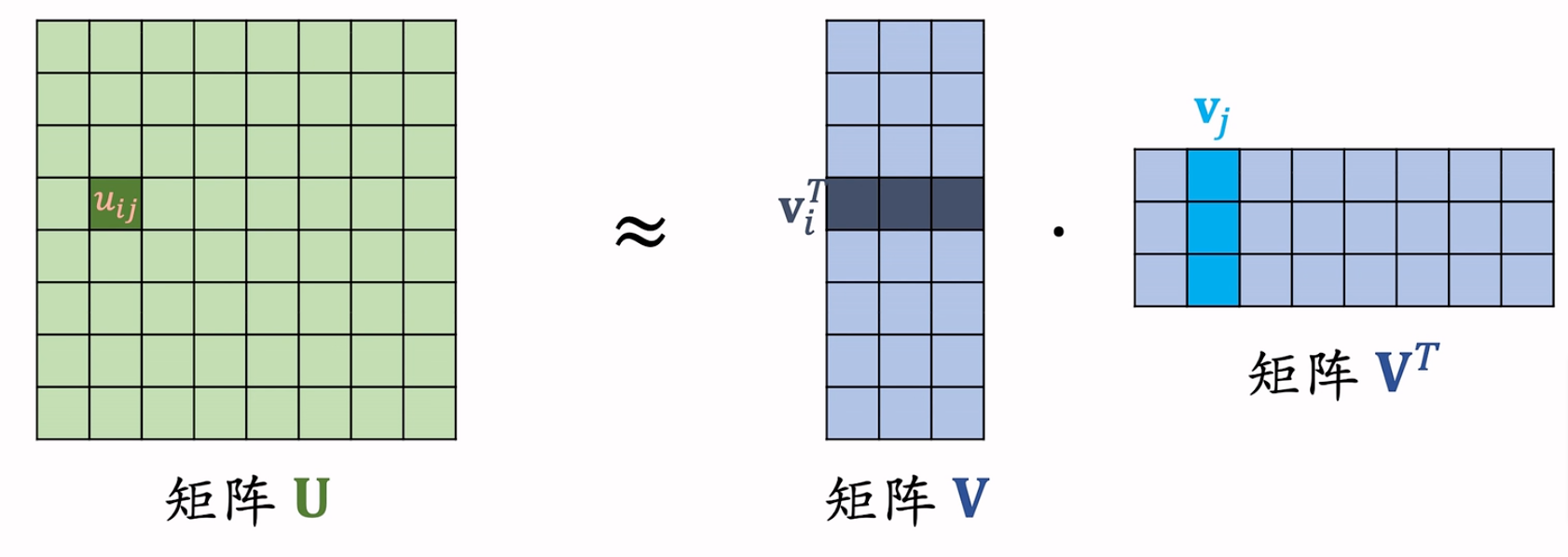
这就是FM。
DCN
交叉层
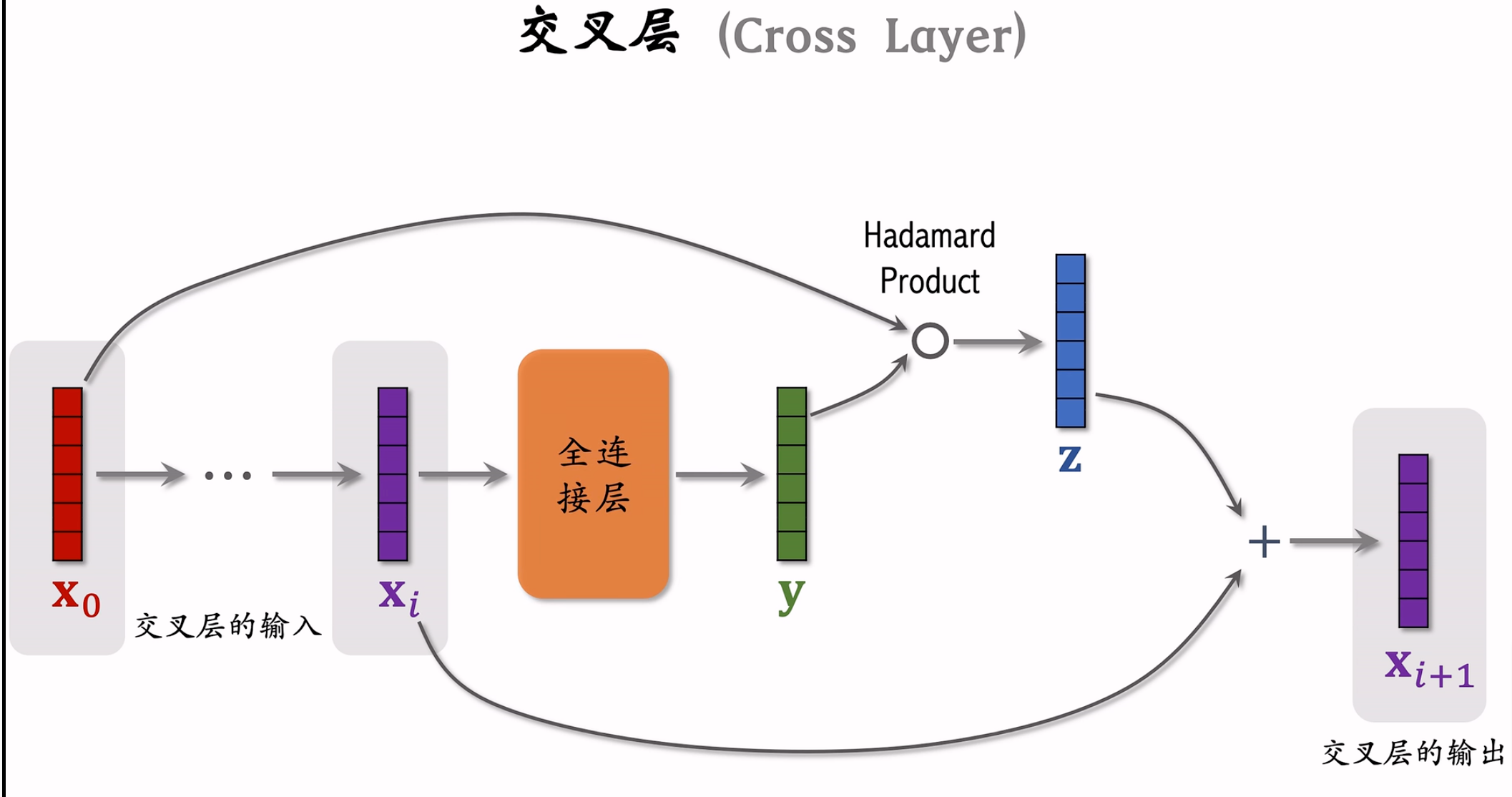
交叉网络(Cross Network)
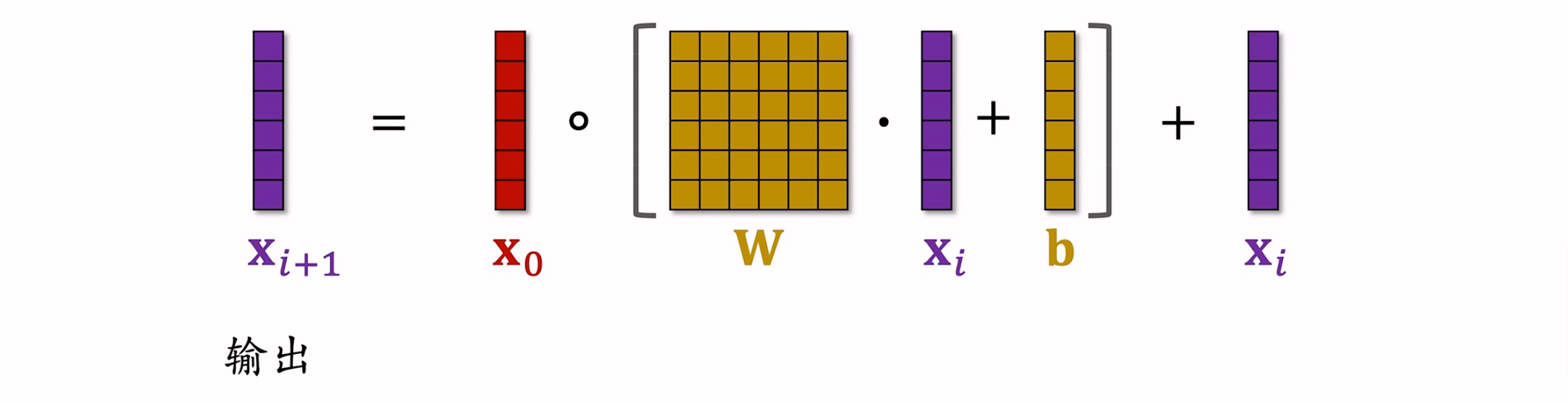
$$
X_1 = X_0 \circ (W_0 * X_0 + b_0) + X_0 \
X_2 = X_0 \circ (W_1 * X_1 + b_1) + X_1 \
X_3 = X_0 \circ (W_2 * X_2 + b_2) + X_2 \
$$
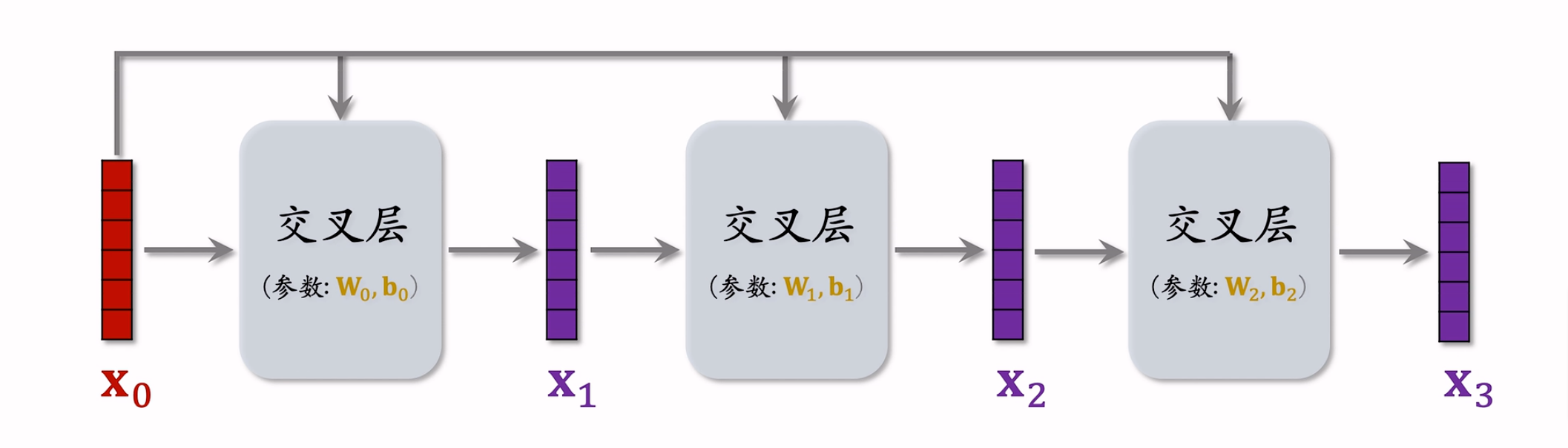
深度交叉网络(DCN)
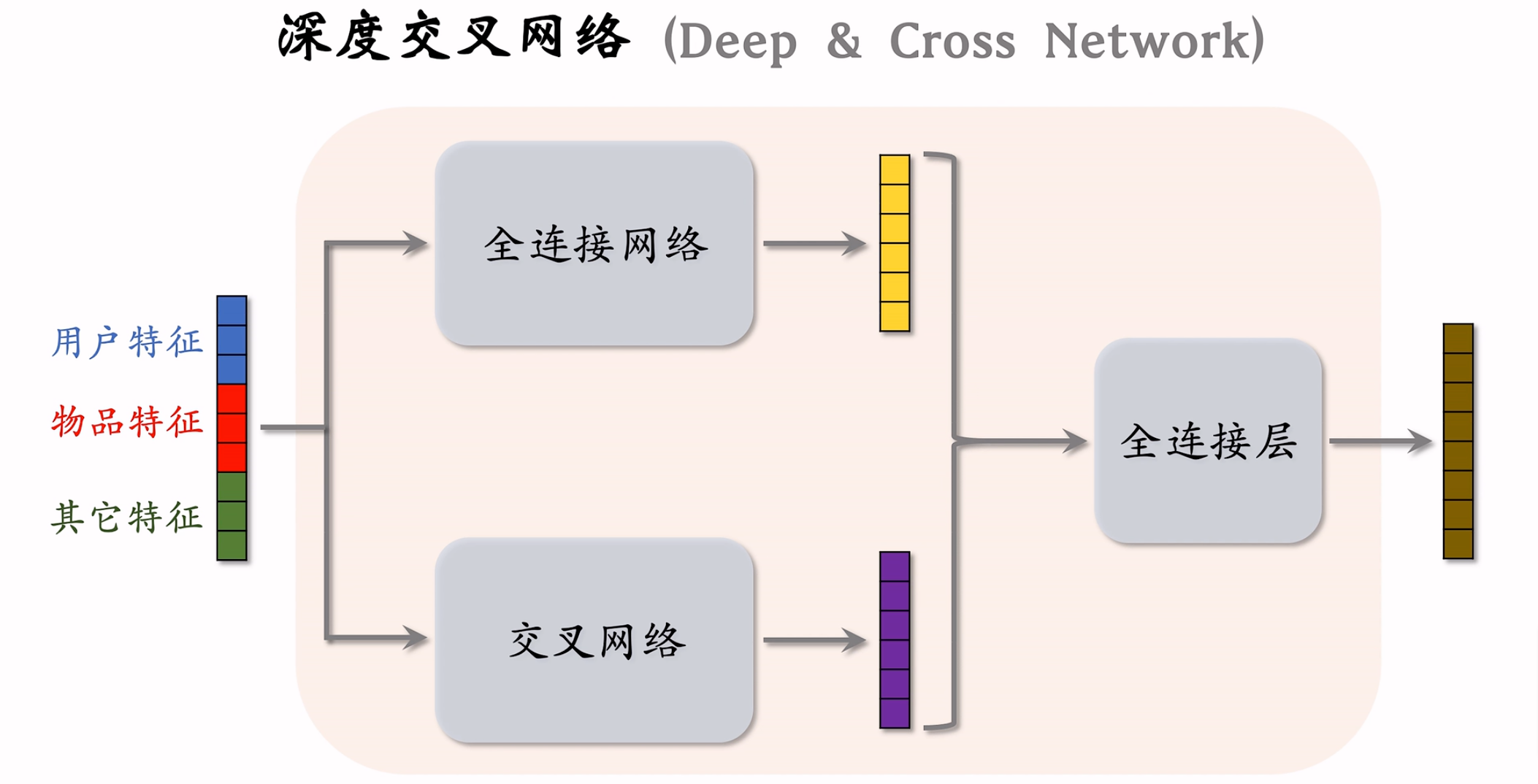
DCN既可以用于召回,也可以用于排序。
双塔模型中的用户塔和物品塔都可以是DCN。
多目标中的Shared Bottoms和MMoE中的专家网络也可以是DCN。
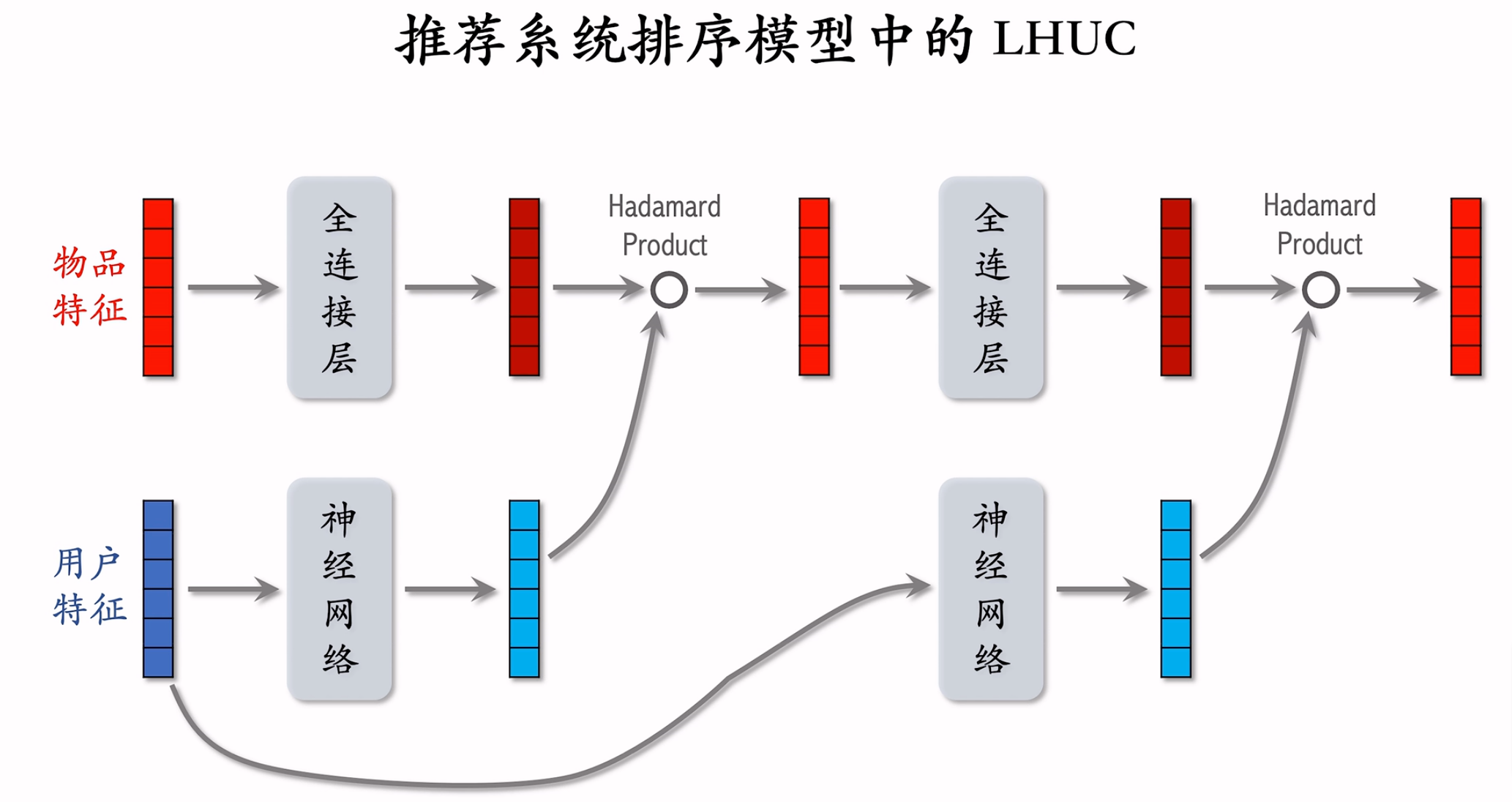
LHUC
LHUC – 2016起源于语音识别,只能用于精排。快手将其用于推荐精排,称为PPNet。
LHUC应用于推荐系统
快手PPNet结构
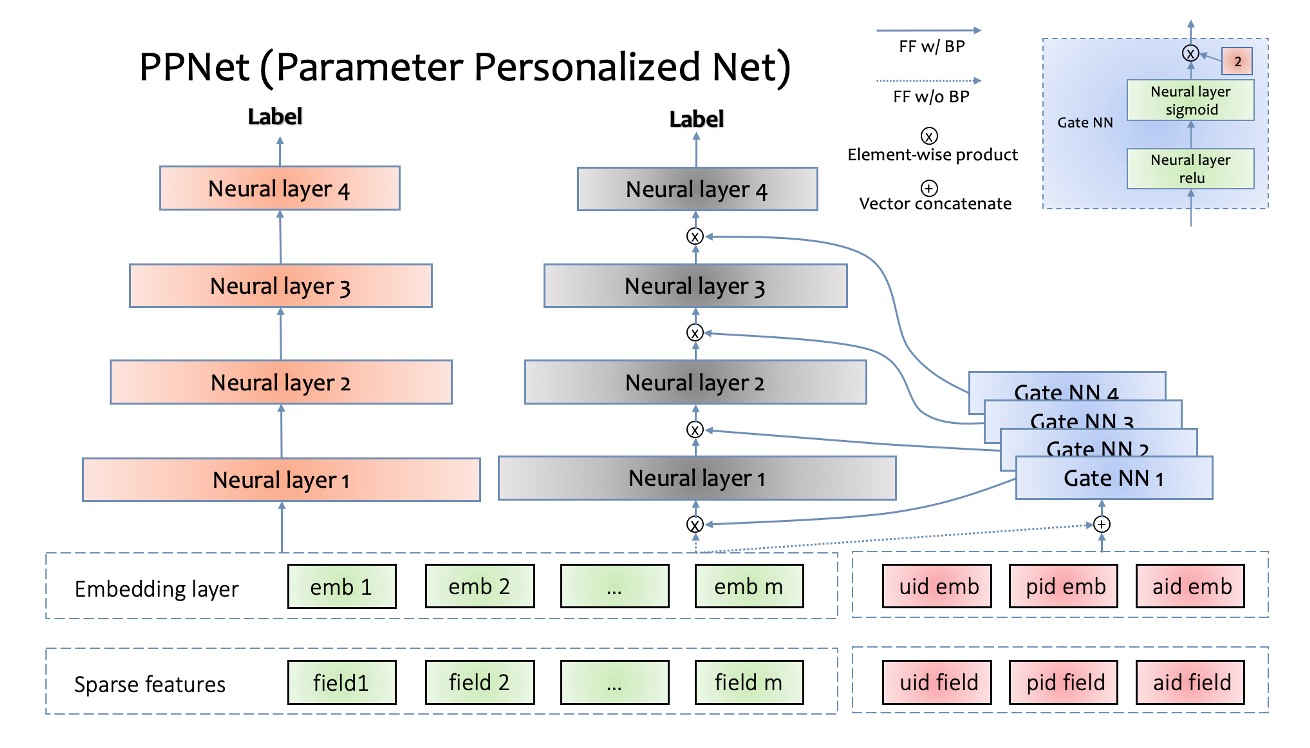
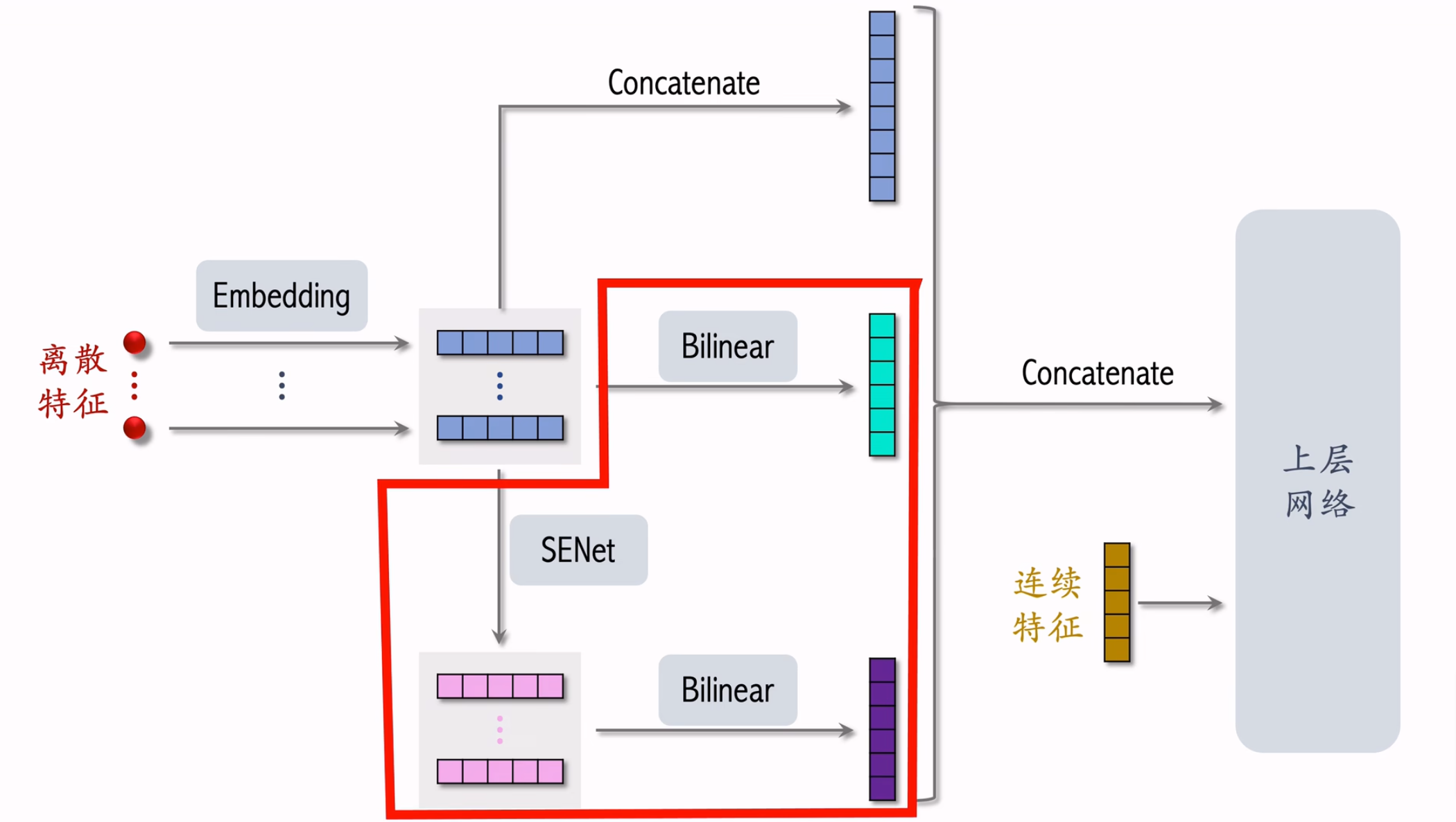
SENet
特征内加权
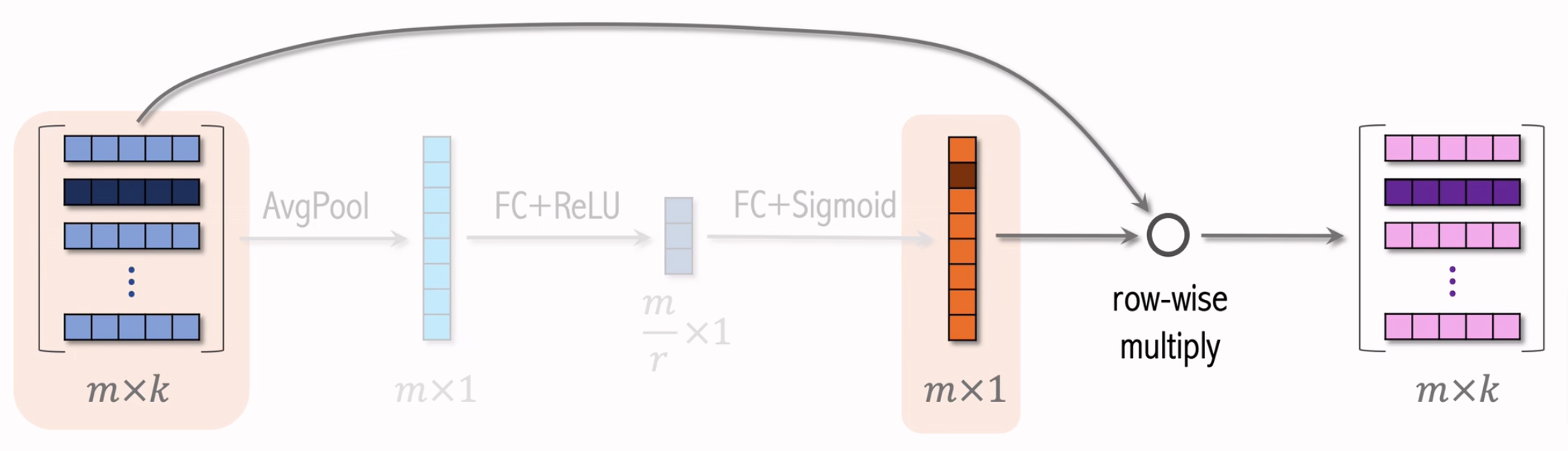
上图是SENet结构图,其中输入的m个离散特征的Embedding向量长度可以不同。
SENet的本质是对离散特征的filed-wise加权。
特征间加权
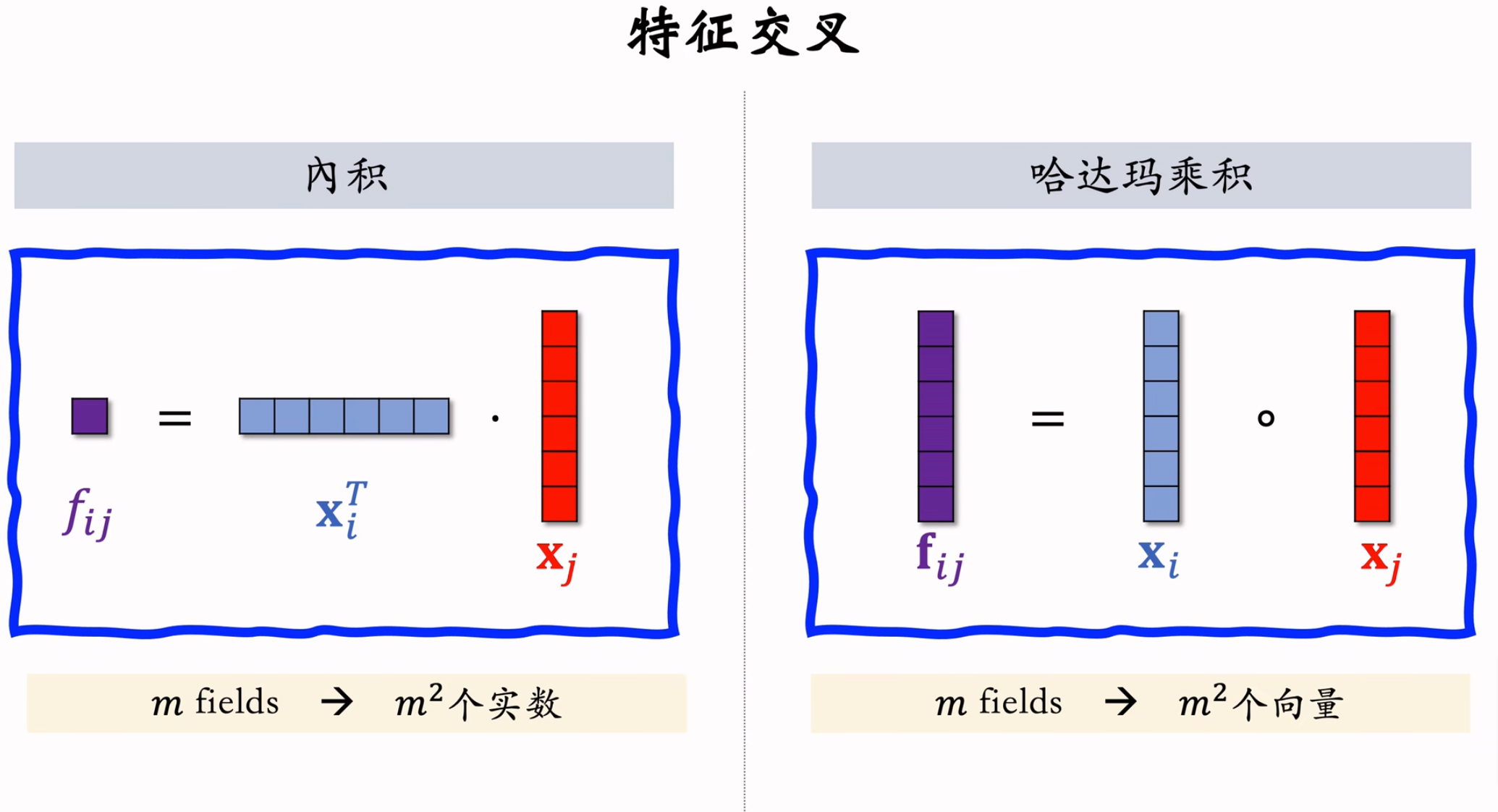
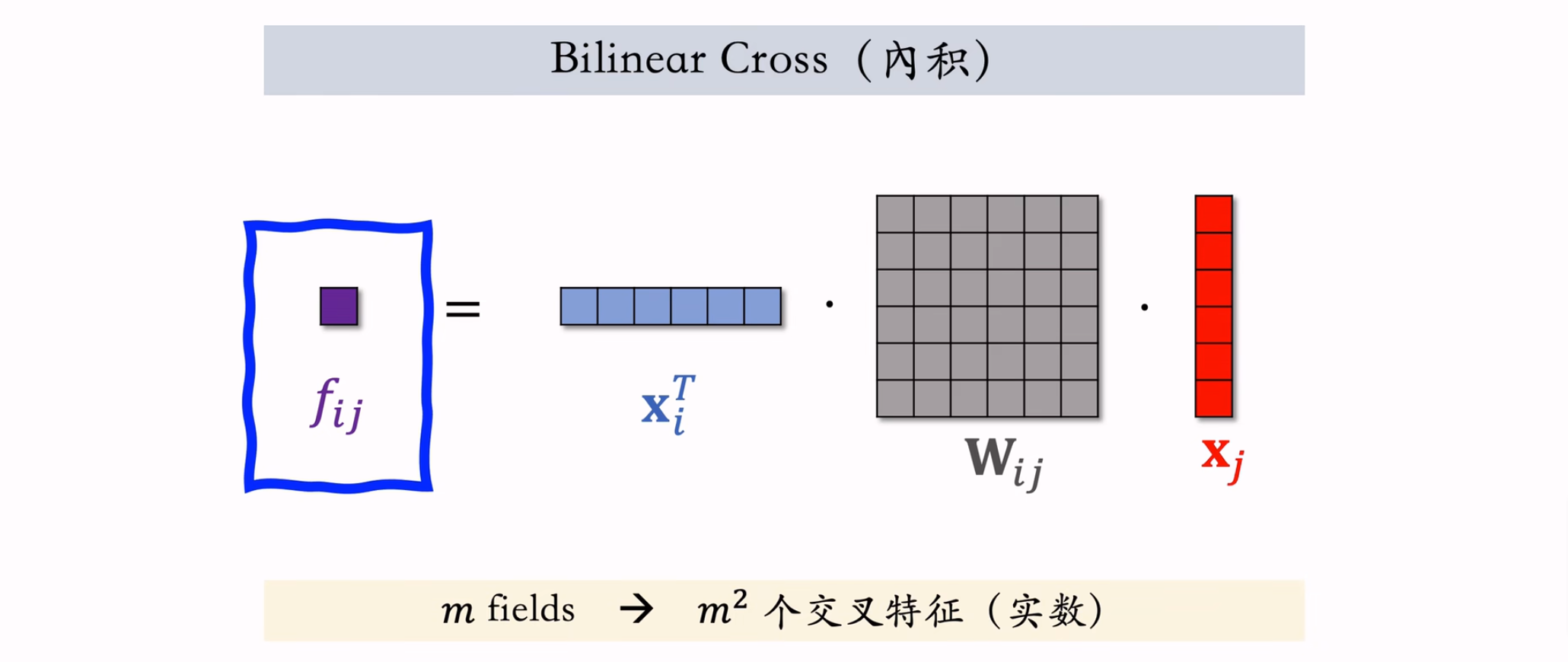
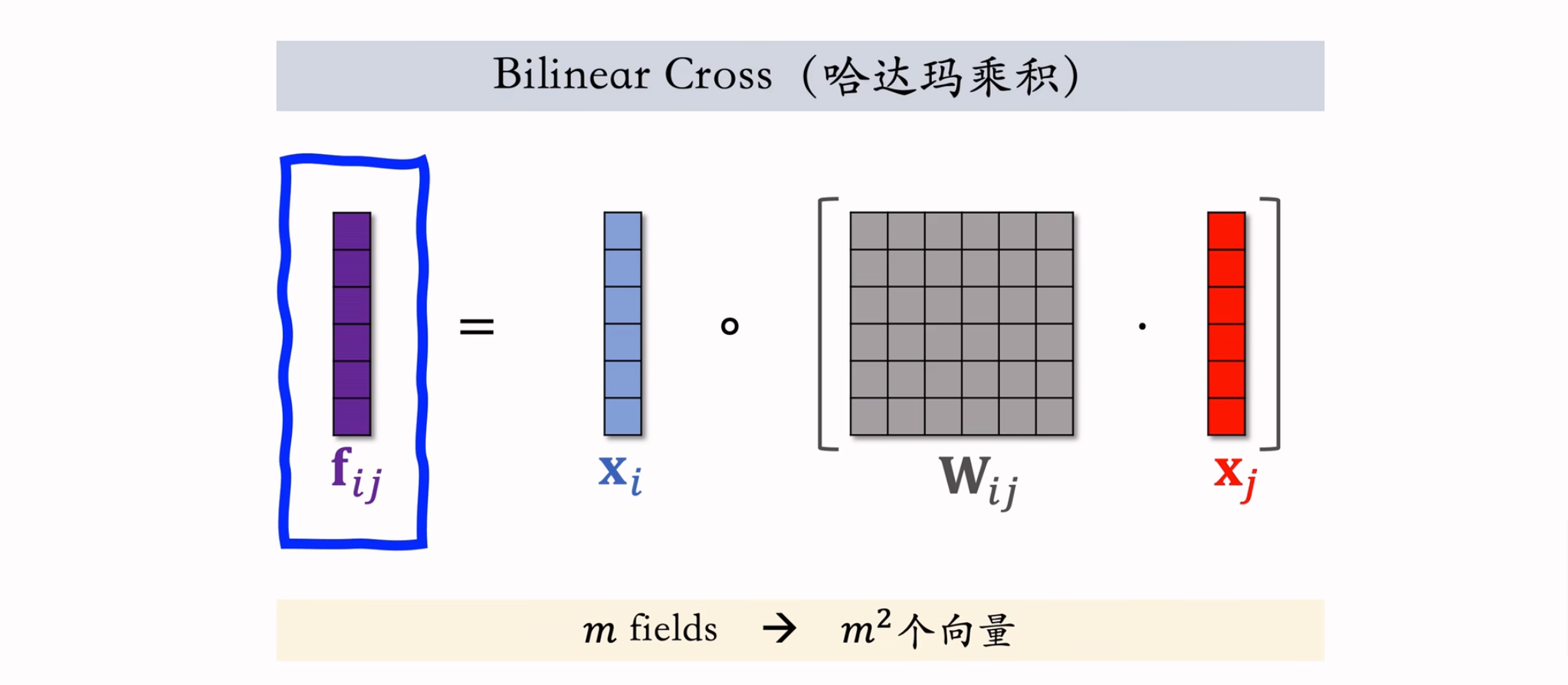
FiBiNet模型
参考文献
公开课地址:GitHub
本文永久更新地址: https://notlate.cn/p/16fca92af3f530cf/
评论