物品冷启动评价指标
物品冷启动目标
- 精准推荐:新物品的推荐效果往往比较差
- 激励发布:新物品得到较多流量后,更容易激励作者。
- 挖掘高潜:从新物品中挖掘高质量物品。
评价指标
- 作者指标:发布渗透量、人均发布量等
- 用户指标:新笔记的交互率、大盘指标(比如日活、月活、时长)
- 内容指标:新物品中的高热笔记占比
简单的召回通道
冷启动难点
- 物品缺少与用户交互行为,难以学好表征向量
- 缺少用户交互,ItemCF不适用
双塔模型改造
- 新物品共用同一个ID,使用default embedding
- 利用相似物品embedding向量,topK个相似的高曝光物品embedding向量均值
类目&关键词召回
聚类召回
通常直接使用向量数据库工具存储物品向量,比如FAISS等,无需自己实现聚类、索引和查找功能。
基本思想
- 事先训练一个神经网络,基于物品的类目和图文内容,把物品映射到向量。
- 对物品向量聚类,记录每个类中心向量。
聚类索引
- 给定一个新物品,用模型将其映射到一个向量
- 从类中心向量中查找属于哪个类,得到类中心向量
- 建立新物品与这个类中心向量的索引
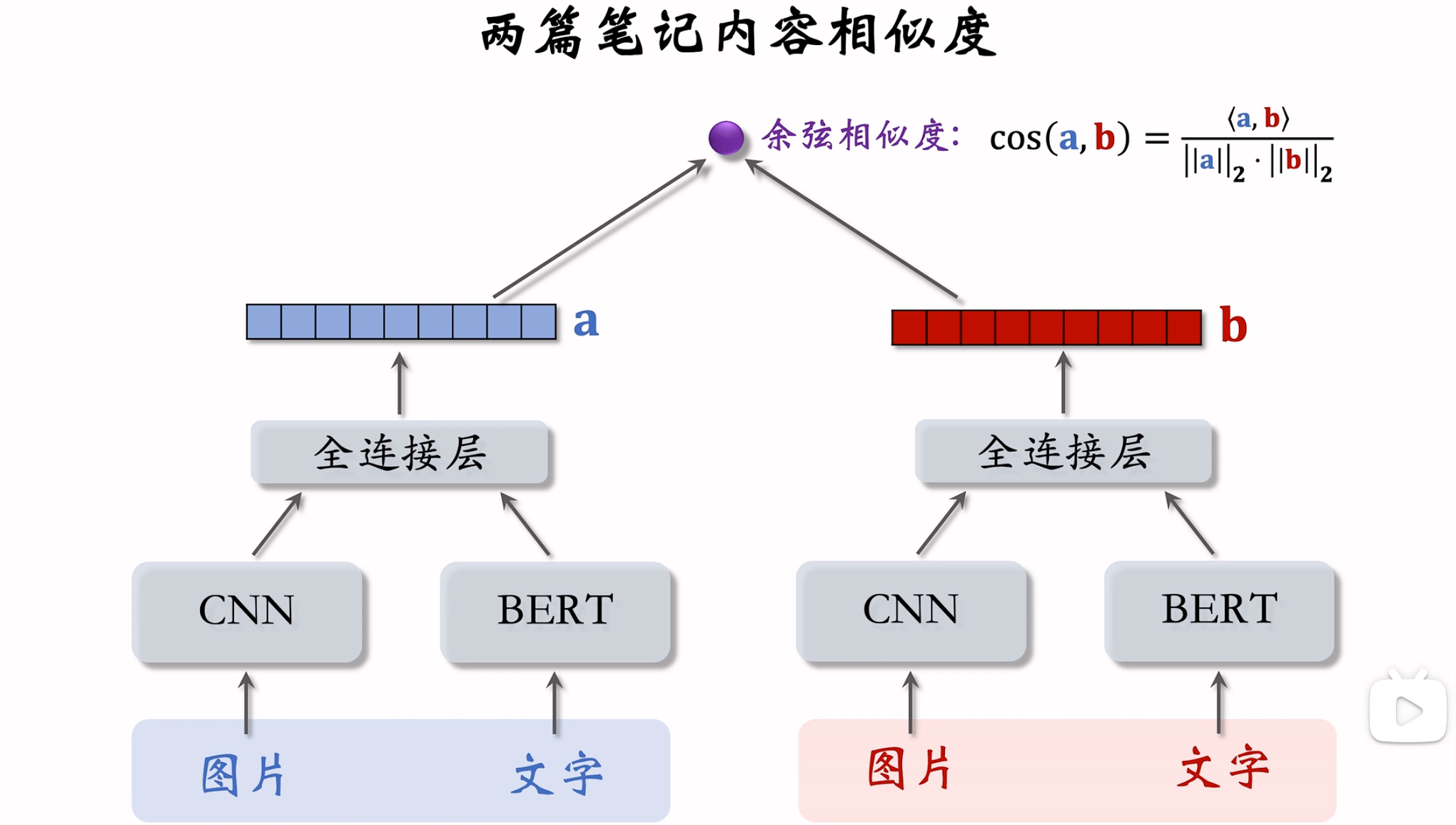
内容相似度
模型结构
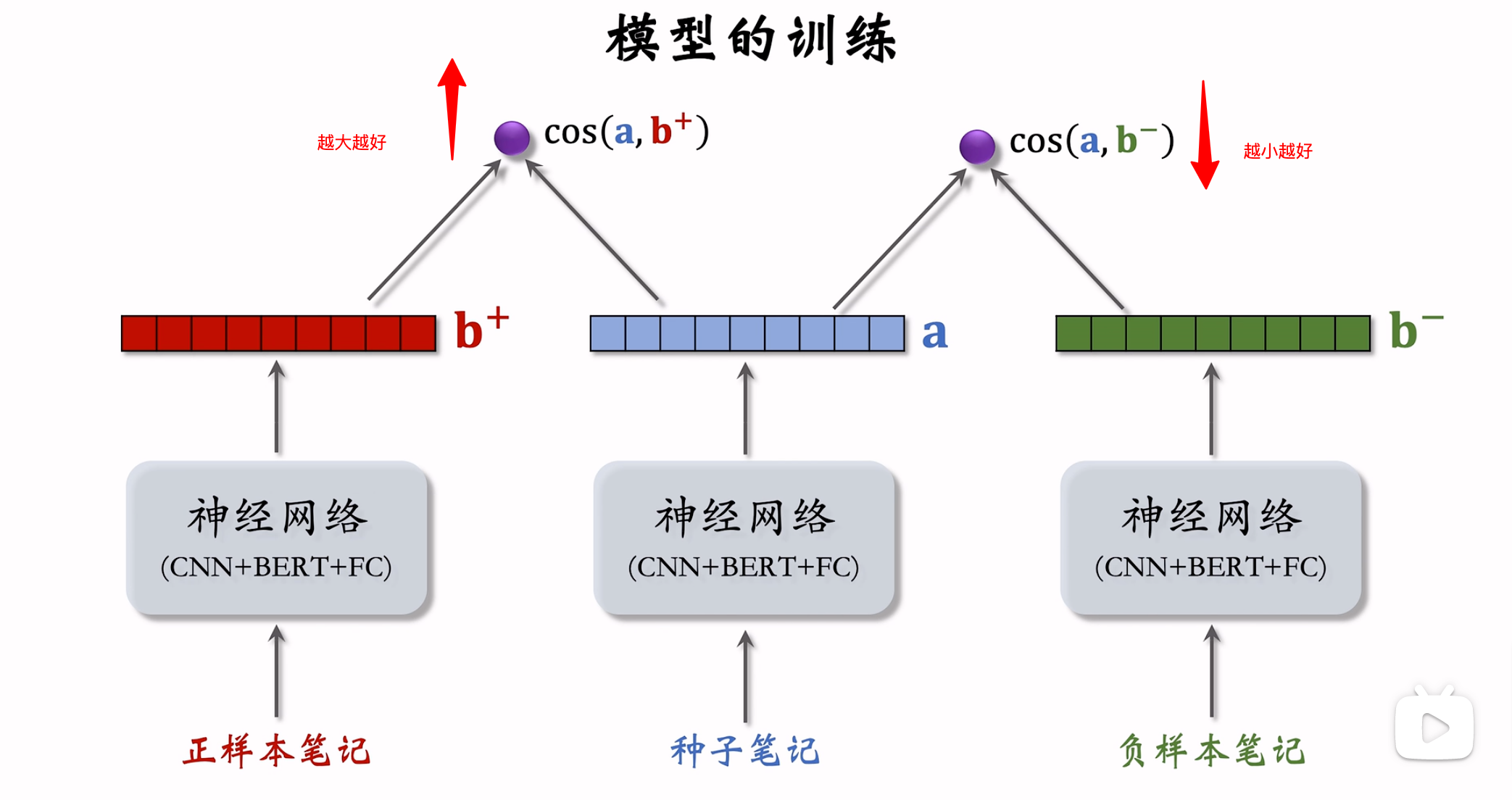
损失函数

样本选取
- 正样本:与高曝光且二级类目相同的笔记组成正样本全集,然后用ItemCF选择相似度高的正样本。
- 负样本:随机挑选,只要字数多、质量高就好。
Look Alike召回
思想:找到种子用户相似的潜在用户。
用户相似度
- UserCF
- 两个用户的Embedding相似度
小红书召回新物品
- 把有交互的用户作为新物品的种子用户
- 找到种子用户的相似用户,然后扩散此新物品
找到相似用户
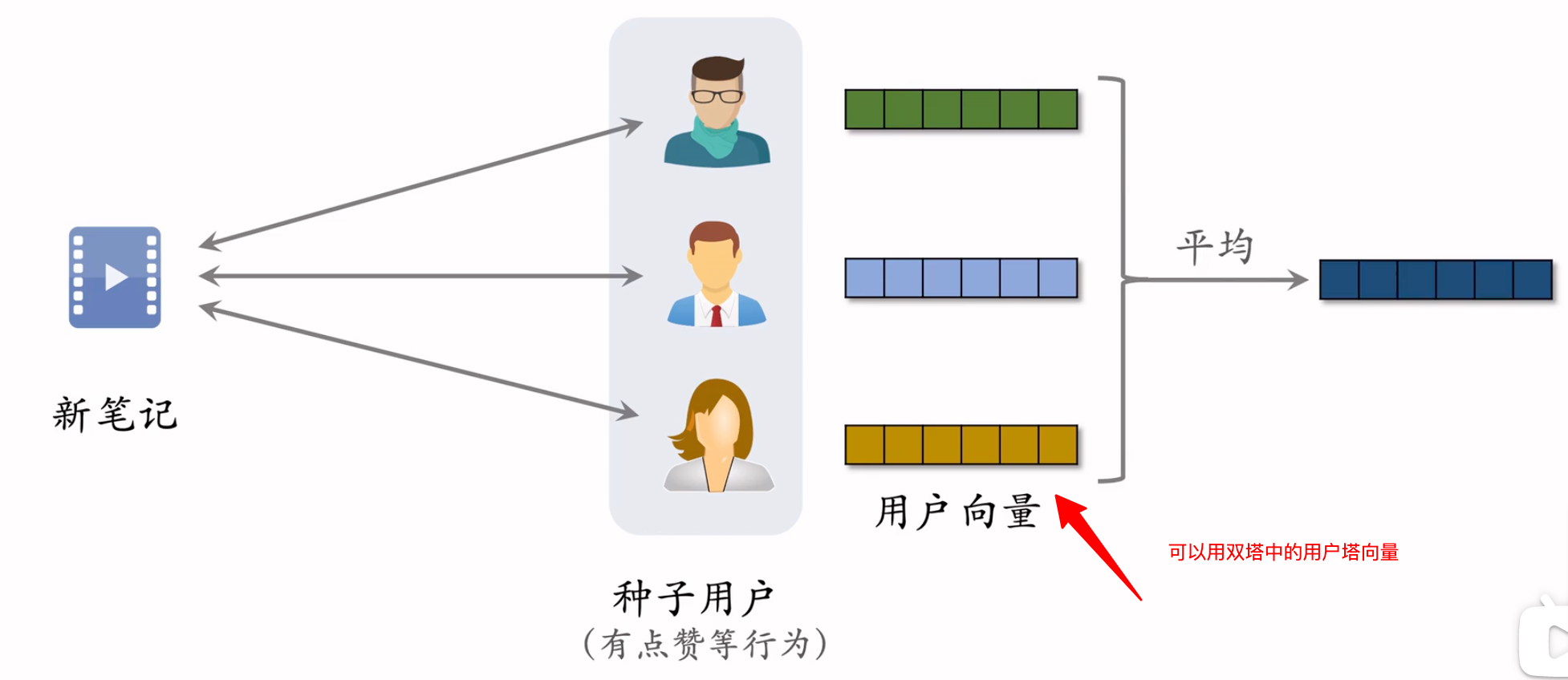
近线更新新笔记的用户向量表征

在线召回
来一个用户,用此用户向量从新物品的用户表征向量中查找最近邻,返回对应的新物品。
流量调控
业界做法
- 在推荐结果中强插新物品
- 对新物品的排序分数做提权(boost)
- 通过提权,对新物品做固定保量
- 差异化保量,根据新物品的质量决定保量目标。
新物品提权
干涉粗排和重排模块。
缺点:曝光量对提权系数敏感,不好精确控制曝光量。
新物品保量
无论质量如何,保证一定时间内曝光一定次数。上线前制定好提权系数与曝光时间和次数策略表,在线实时获取提权系数。
动态提权保量
根据目标时间、目标次数、已发布时间和已曝光次数动态计算提权系数。
为什么不用暴力提权?
好处:分数提升多,保量易满足
坏处:把物品推荐给不合适的人群反而影响后续效果
差异化保量
在动态提权基础上,用模型评价模型质量,额外增加保量次数;或者根据作者质量,额外增加保量次数。
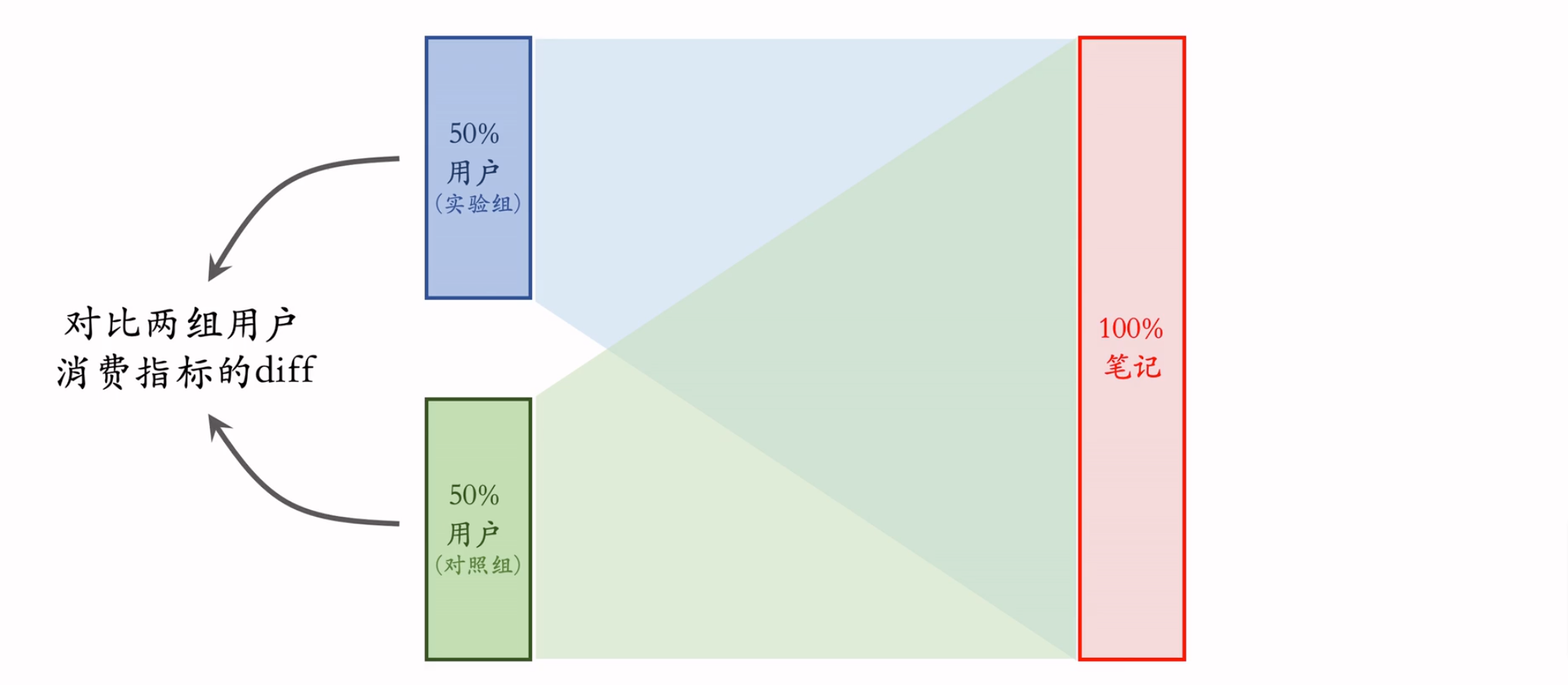
AB测试
标准的AB
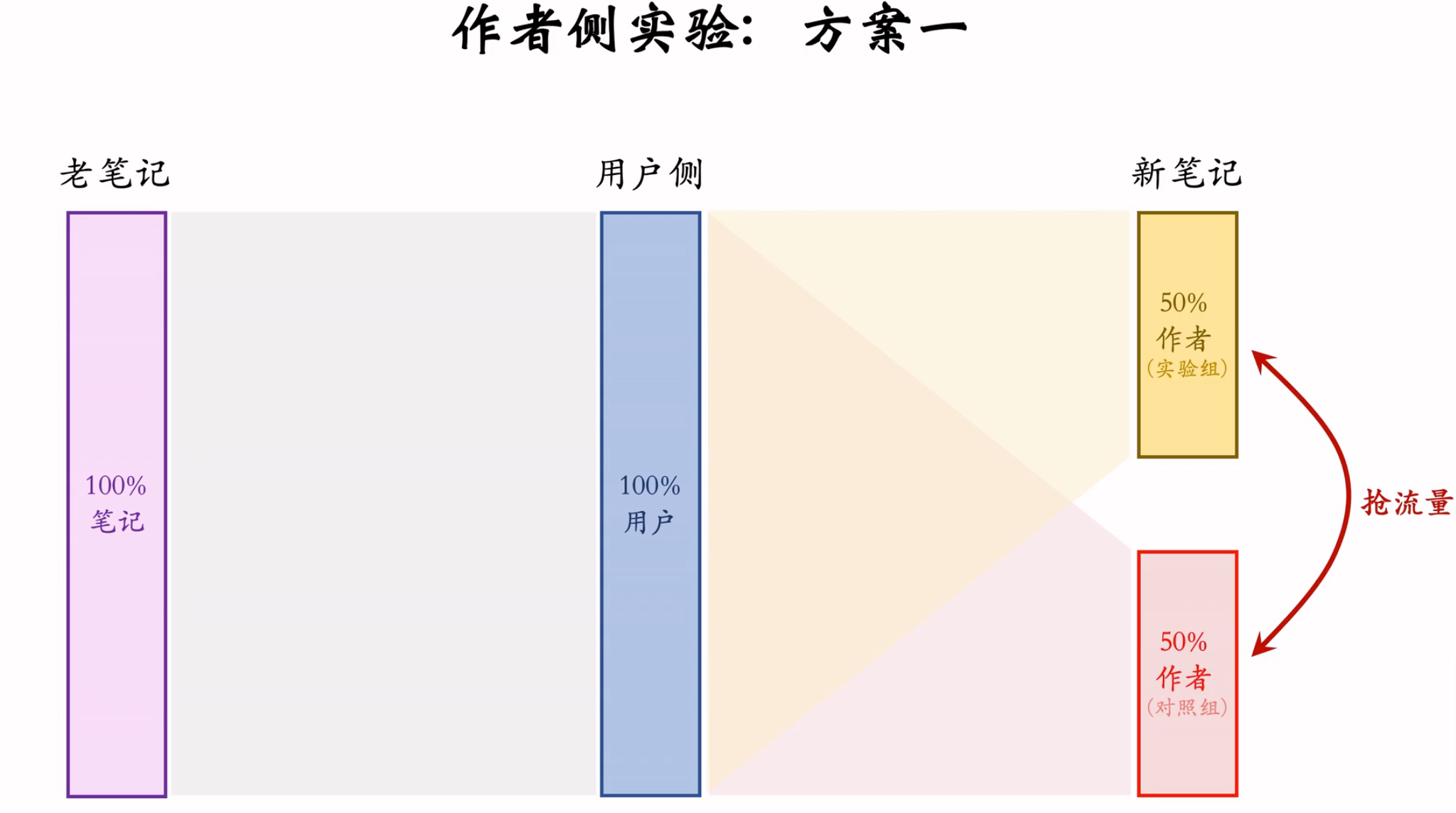
作者侧 方案一
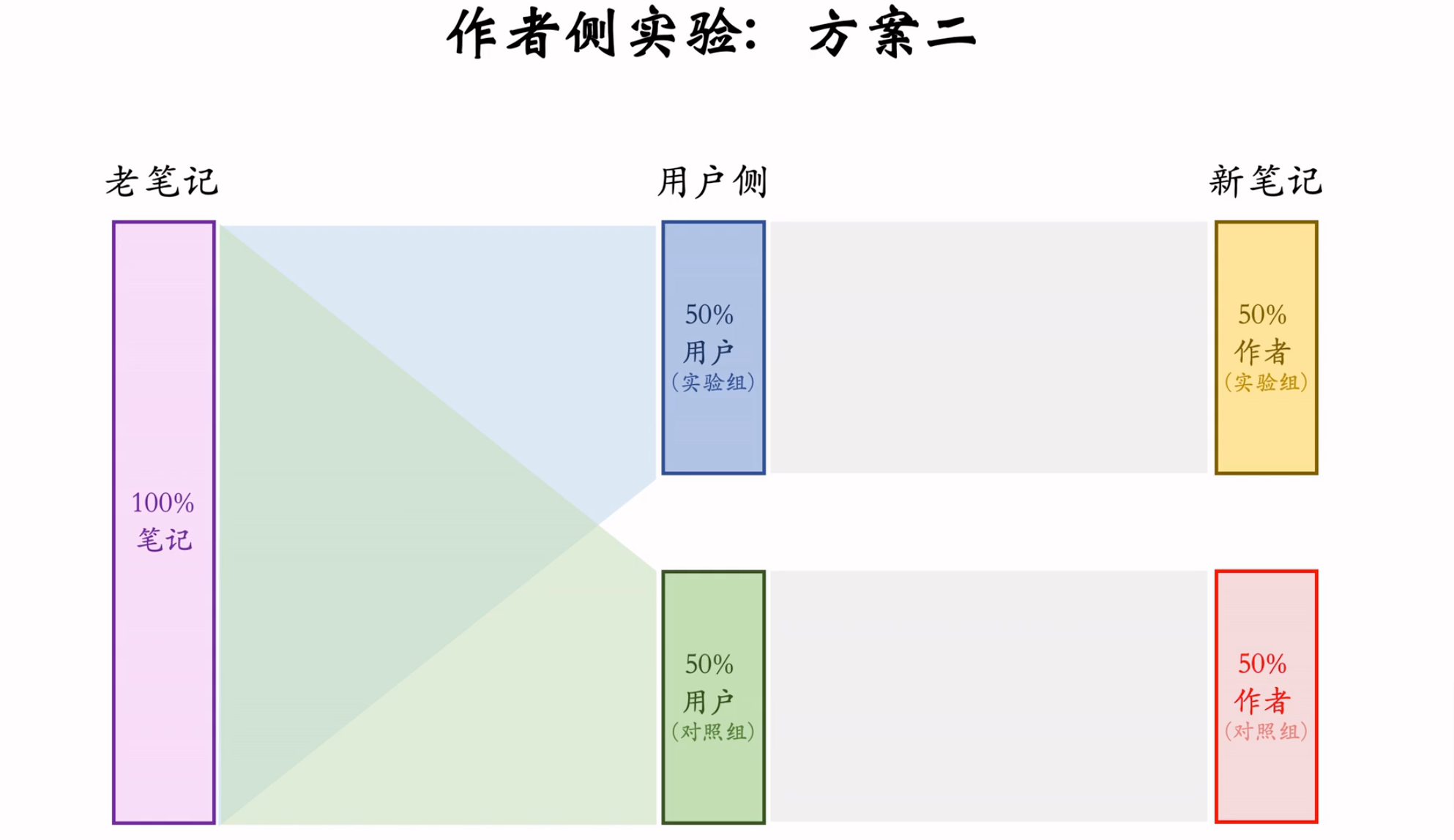
作者侧 方案二
参考文献
公开课地址:GitHub
本文永久更新地址: https://notlate.cn/p/3af1eb0c0612632c/