简单平均
lastN特征
把用户最近n次交互的物品Embedding向量取平均,作为一个用户特征使用。
适用于召回双塔模型、粗排三塔模型、精排模型。
DIN
原理
本质:用加权平均代替平均,也就是注意力机制。
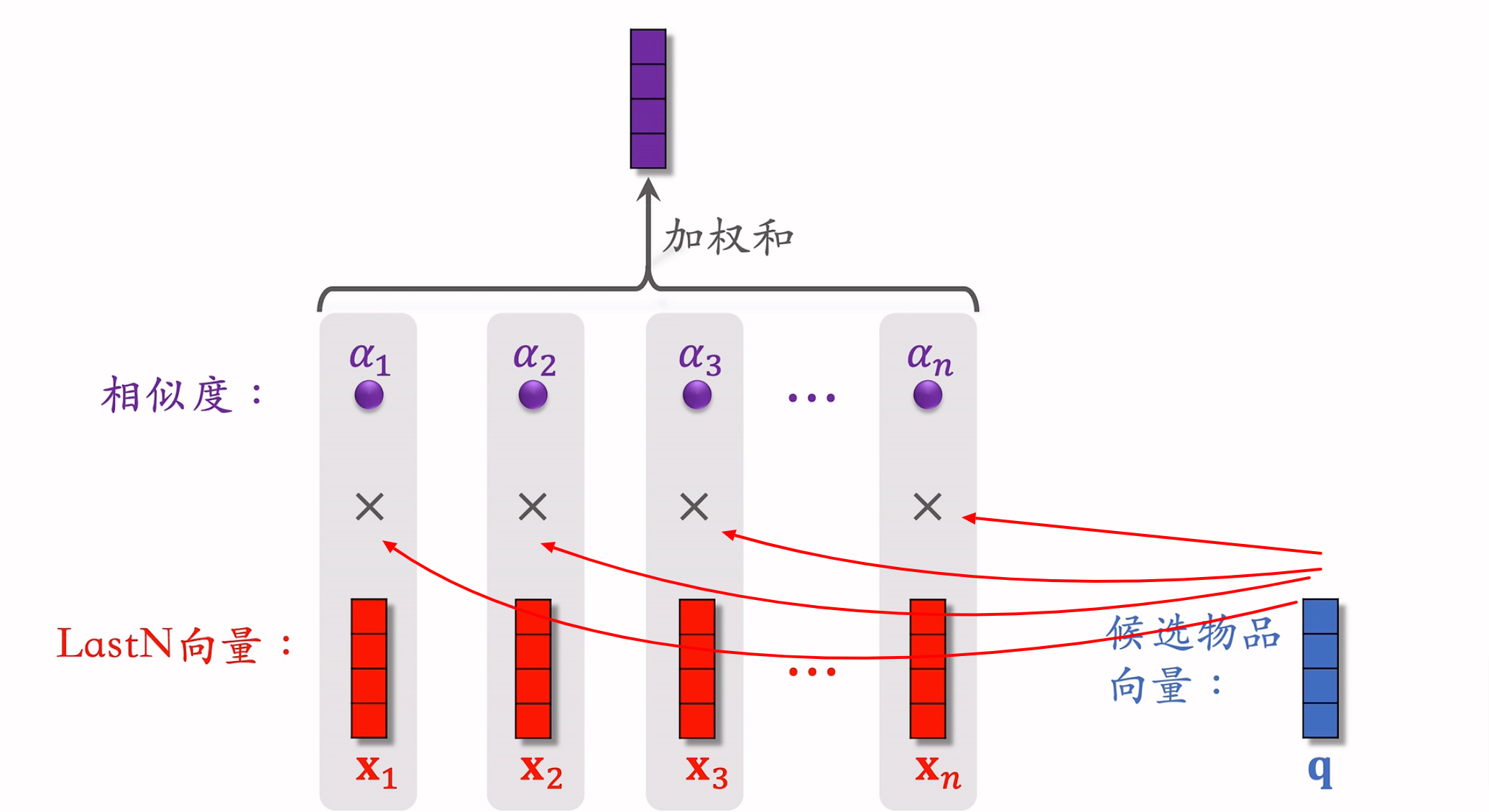
注意力机制不适用于召回双塔和粗排三塔。因为需要用到候选物品,而用户塔看不到候选物品。
缺点
注意力层需要计算全部LastN个物品的相似度,计算量与用户序列长度呈正比。所以只能记录用户最近有限个物品,否则计算量太大。
由上可知DIN模型只能关注到用户的短期兴趣,遗忘掉用户长期兴趣。
SIM模型(DIN改进)
原理
本质:排除掉与候选物品无关的LastN物品,降低注意力层的计算量。参考文献《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》。
步骤
查找
-
Hard Search。根据候选物品的类目,保留LastN物品中相同类目的物品。简单快速,无需训练。通常这个方法就足够了。
-
Soft Search。把物品做成Embedding向量,用K近邻查找最近k个物品。
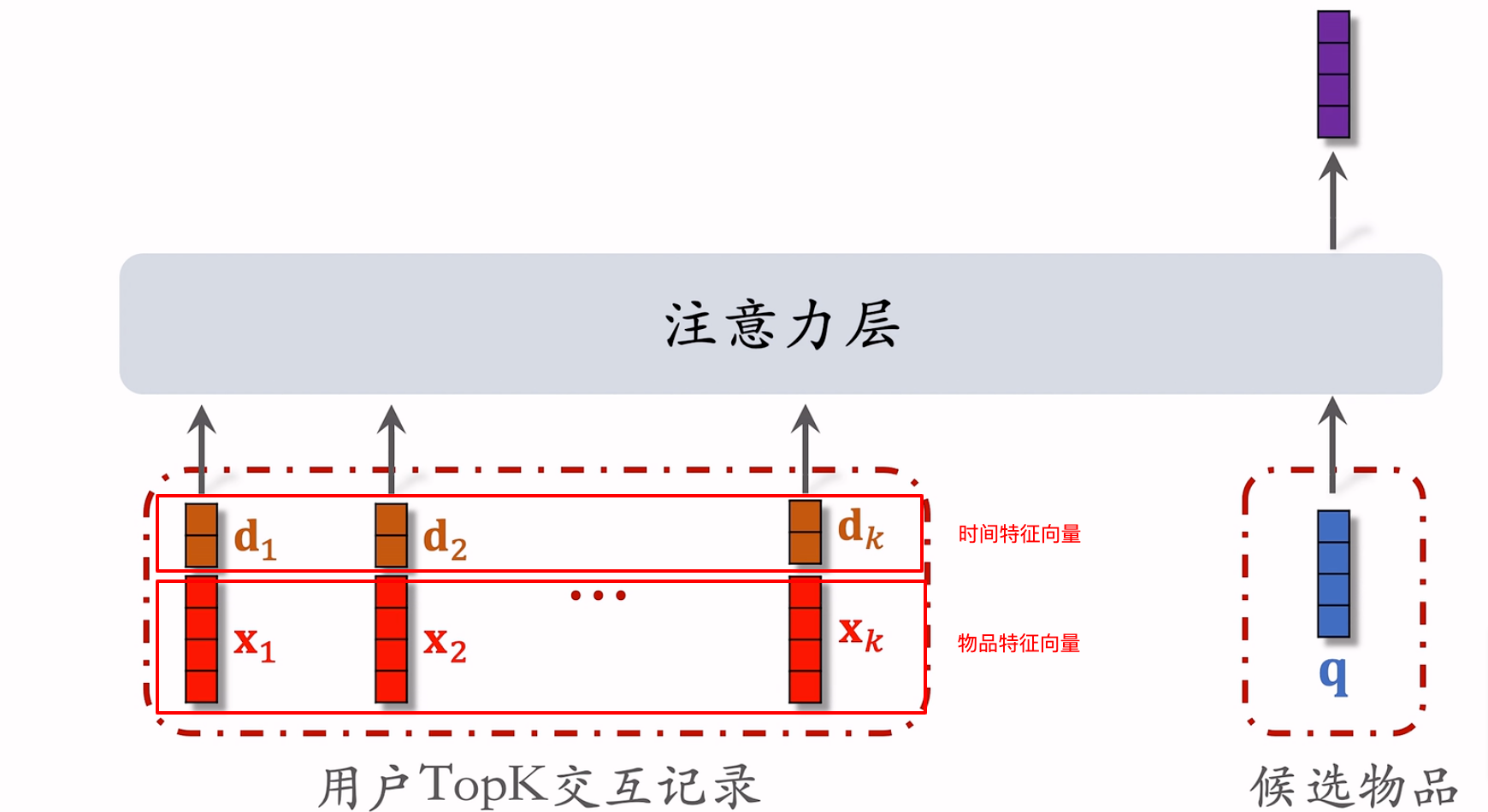
注意力机制
-
使用第一步中查找出的topK个物品作为输入。
-
增加用户与某个物品的交互时间至今的时间差特征。因为输入包含了用户长期的交互序列,所以有的物品可能距离当前时刻比较久远。把时间特征做成embedding向量后,拼接到物品向量上即可。行为序列中的物品embedding和候选物品embedding的size大小不一致没关系,无论通过哪种手段,只要让注意力层输出一个表示注意力大小的标量值即可。
参考文献
公开课地址:GitHub
本文永久更新地址: https://notlate.cn/p/773215a847ca8a36/
评论