1. 协同过滤(CF)
1. 里程碑
2003年,Amazon发表论文《Amazon.com recommendations: item-to-item collaborative filtering》,不仅让Amazon的推荐系统广为人知,更让协同过滤成为今后很长时间的研究热点和业界主流的推荐模型。
2. 算法过程
(1)一种完全依赖用户和物品之间行为关系的推荐算法,利用所有用户与所有商品的关系创建共现矩阵。
(2)计算用户相似度:在共现矩阵中,每个用户对应的行向量其实就可以当作一个用户的 Embedding 向量,可以使用余弦相似度计算。
(3)用户评分预测:利用用户相似度与相似用户评价的加权平均值,来获得目标用户的评价预测
3. 缺点
共现矩阵往往非常稀疏
2. 矩阵分解
1. 里程碑
2006年,在Netflix Prize Challenge中,以矩阵分解为主的推荐算法大放异彩,拉开了矩阵分解在业界流行的序幕。
2. 协同过滤与矩阵分解区别

(1)协同过滤算法(图左)找到用户可能喜欢的视频的方式很直观,就是利用用户的观看历史,找到跟目标用户 Joe 看过同样视频的相似用户,然后找到这些相似用户喜欢看的其他视频,推荐给目标用户 Joe
(2)矩阵分解算法(图右)是期望为每一个用户和视频生成一个隐向量,将用户和视频定位到隐向量的表示空间上,距离相近的用户和视频表明兴趣特点接近,在推荐过程中,我们就应该把距离相近的视频推荐给目标用户
3. 矩阵分解过程
先分解协同过滤生成的共现矩阵,生成用户和物品的隐向量,再通过用户和物品隐向量间的相似性进行推荐。把一个$M * N$的共现矩阵,分解成一个$MK$的用户矩阵和$KN$ 的物品矩阵相乘的形式。
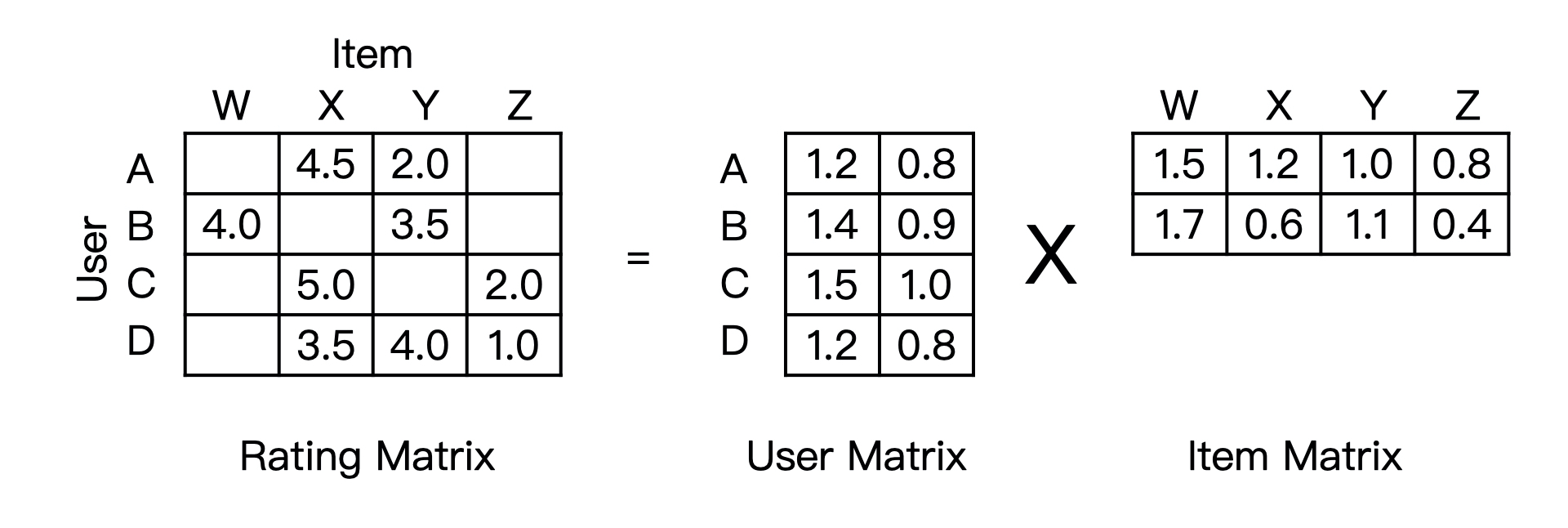
4. 分解方法
(1)特征值分解(ED):只能作用于方针,不适用于分解用户-物品矩阵
(2)奇异值分解(SVD):要求原始的共现矩阵是稠密的,而且计算复杂度达到了$O(mn^2)$,因此不满足实时性要求
(3)梯度下降法(GD):主要方法,为了减少过拟合现象,通常加入正则化项。
5. 矩阵分解优点:
(1)泛化能力强,在一定程度上解决了数据稀疏的问题
(2)空间复杂度低,不需要存储大量的用户和物品相似性矩阵,只需要存储用户和物品隐向量即可。
(3)更好的扩展性和灵活性:矩阵分解结果是用户和物品隐向量,与Embedding思想不谋而合,因此其结果易于与其他特征交叉组合,也能够与深度学习网络无缝结合。
6. 矩阵分解局限性
不方便加入用户、物品和上下文相关的特征,丧失了利用很多有效信息的机会。同时在缺乏用户历史行为时无法进行有效推荐。
7. 问答经典
- 评分标准不一致,有人喜欢打高分,有人喜欢打低分,如何处理?
(1)在生成共现矩阵的时候对用户的评分进行用户级别的校正或者归一化,用当前得分减去用户平均得分作为共现矩阵里面的值
(2)可以尝试余弦相似度消除影响。
- 正负样本不平衡问题怎么处理?
(1)负样本欠采样,和正样本过采样,或者增大正样本学习的权重。
(2)SMOTE,大致意思是通过合成的方式过采样正样本,可以尝试但有一定风险。
3. 逻辑回归(LR)
1. 简介
LR模型可以综合利用用户、物品、上下文等多种不同的特征。另外LR的另外一种表现形式“感知机”是神经网络中最基础的单一神经元结构,是深度学习的基础结构。LR把推荐问题看作分类问题,通过预测正样本的概率对物品进行排序,因此转化成了点击率(CTR)预估问题。
2. 推荐流程
(1)将用户属性信息、物品属性信息、上下文属性信息等特征展开并转换成数值型特征向量。
(2)确定LR模型的优化目标,利用已有样本数据对LR模型进行训练。
(3)模型服务阶段,将特征向量输入LR模型,推断得到目标概率。
(4)利用概率对所有候选物品进行排序,得到推荐列表。
3. 具体LR模型数学表达及训练方法,请参考:
深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-03-基于Python的LeNet之LR
4. LR模型的优势
(1)可解释性强。LR模型数学形式是各特征的加权和,在经过Sigmoid函数计算出0~1之间的概率,符合人类对预估过程的直觉人知。
(2)工程化需要。在互联网公司每天数据量是TB级别,模型的训练和在线推断效率非常重要。在尚未流行GPU训练(2012年)之前,LR模型凭借易于并行化、模型简单、训练开销小等优势占据着工程领域的主流。
5. LR模型局限性
表达能力不强,无法进行多特征交叉、特征筛选等复杂操作;
4. 因子分解机(FM)
1. 为什么需要多特征交叉?
辛普森悖论 — 交叉与不交叉的结论完全相悖
2. 特征交叉发展里程碑
POLY2–>FM–>FFM
3. POLY2模型
原始的特征交叉方法是人工组合特征,再通过各种分析手段筛选有效的组合特征。因此首先发展出了POLY2(Degree-2 Polynomial Margin,论文链接)模型进行特征的“暴力”组合。数学形式如下:
$$
POLY2(w, x) = w_0 + \sum^{n}{i=1} w_i x_i + \sum^{n}{j_1 = 1} \sum^{n}{j_2 = j_1 + 1} w{h(j_1, j_2)} x_{j_1} x_{j_2}
$$
其中$n$表示特征数量,$x_i$表示one-hot编码中第$i$个特征的值,$w$等是模型参数。
当$x_{j_1}$和$x_{j_2}$两者都非零时,交叉特征$x_{j_1} x_{j_2}$才有效。上式对特征进行了两两交叉(特征$x_{j_1}$和$x_{j_2}$),并对所有的交叉特征赋予权重$w_{h(j_1, j_2)}$。
在一定程度上解决了特征交叉的问题,但本质上还是线性模型,其训练方法与LR无区别。同时存在2个较大缺陷:
(1)one-hot编码处理类别型数据导致特征向量稀疏,POLY2进行无选择的特征交叉会导致特征向量更加稀疏。
(2)权重参数数量由$n$上升到了$n^2$,极大的增加了训练复杂度。
4. FM模型
2010年,Rendle提出了FM模型(Factorization Machines),FM为每个特征学习一个隐权重向量,在特征交叉的时候,使用两个特征隐向量的内积作为交叉特征的权重,而不是PLOY2中为每个交叉特征设置一个权重参数,数学形式如下:
$$
FM(w, x) = w_0 + \sum^{n}{i=1} w_i x_i + \sum^{n}{j_1 = 1} \sum^{n}{j_2 = j_1 + 1} (\vec{w{j_1}} \cdot \vec{w_{j_2}}) x_{j_1} x_{j_2}
$$
与POLY2的主要区别是:用两个向量的内积$(\vec{w_{j_1}} \cdot \vec{w_{j_2}})$取代了单一的权重系数$w_{h(j_1, j_2)}$。FM引入隐向量的思路与矩阵分解出用户隐向量和物品隐向量思路一致,但是做了进一步的拓展,即从单纯的用户、物品两特征拓展到了所有的特征。
优点:
(1)把POLY2的$n^2$级别参数量降低到了$nk(k是隐向量维度,n>>k)$级别,大大降低了训练开销。
(2)引入隐向量,可以更好的解决稀疏数据问题。可以把两种特征的向量内积作为交叉特征的权重,而不需要样本中必须含有这种交叉特征。
(3)一定程度上丢失了某些具体交叉特征的精确记忆表示能力,但是大大提高了泛化能力。
由于FM同样可以用梯度下降方法进行训练,其二阶表达式经过化简之后,预测复杂度可从$O(kn^2)$优化到$O(kn)$,即可以在线性时间内完成线上预测。同时计算完梯度后的表达式复杂度是$O(kn)$,因此其训练也非常高效。所以凭借着易于训练和预测,所以在2012~2014年前后成为业界主流的推荐模型之一。
5. FFM
2015年,基于FM提出的FFM(Field-aware Factorization Machines for CTR Prediction)在多项CTR预估大赛中夺冠,并被Criteo、美团等公司深度应用在推荐系统、CTR预估等领域。FFM引入了特征域概念,使模型的表达能力更强。那怎么理解特征域呢?
《深度学习推荐系统》中的示例:
用户的性别分为男、女、未知三类,那么对一个女性用户来说,采用one-hot方式编码的特征向量为[0, 1, 0],这个三维的特征向量就是一个“性别”特征域。
《深入FFM原理与实践》中的解释:
以上面的广告分类为例,“Day=26/11/15”、“Day=1/7/14”、“Day=19/2/15”这三个特征都是代表日期的,可以放到同一个field中。同理,商品的末级品类编码生成了550个特征,这550个特征都是说明商品所属的品类,因此它们也可以放到同一个field中。简单来说,同一个categorical特征经过One-Hot编码生成的数值特征都可以放到同一个field,包括用户性别、职业、品类偏好等。
我的个人理解是:经过one-hot编码的某类特征的特征值的集合称为特征域。
FFM的数学形式如下:
$$
FFM(w, x) = w_0 + \sum^{n}{i=1} w_i x_i + \sum^{n}{j_1 = 1} \sum^{n}{j_2 = j_1 + 1} (\vec{w{j_1, f_{j_2}}} \cdot \vec{w_{j_2, f_{j_1}}}) x_{j_1} x_{j_2}
$$
其中:
(1)$f_j$表示第$j$个特征所属的特征域;
(2)$\vec{w_{j_1, f_{j_2}}}$表示特征$x_{j_1}$与特征域$f_{j_2}$对应的隐向量,同理$\vec{w_{j_2, f_{j_1}}}$表示特征$x_{j_2}$与特征域$f_{j_1}$对应的隐向量。
因此FFM与FM的区别是隐特征向量由$\vec{w_{j_1}}$变成了$\vec{w_{j_1, f_{j_2}}}$,意味着每种特征都会针对其他特征域学习一个隐向量。当$x_{j_1}$和$x_{j_2}$两种特征进行交叉时,$x_{j_1}$挑出与$x_{j_2}$所属特征域$f_{j_2}$的隐向量$\vec{w_{j_1, f_{j_2}}}$与$x_{j_2}$挑出与$x_{j_1}$所属特征域$f_{j_1}$的隐向量$\vec{w_{j_2, f_{j_1}}}$进行交叉计算。
FFM模型在训练时,需要学习$n$个特征在$f$个域上的$k$维隐向量,则二阶参数量有$n \cdot f \cdot k$个,且由于隐向量和域相关,FFM的二阶部分不能化简,所以预测复杂度是$O(kn^2)$。
FFM实际特征交叉举例:

5. GBDT+LR
1. 简介
FFM模型增加了特征交叉能力,但是只能做二阶特征交叉,若提高特征交叉的维度,则会产生组合爆炸和计算复杂度过高的问题。2014年,Facebook提出了基于GBDT+LR组合模型的解决方案,其中用GBDT自动进行特征筛选和组合,再把特征向量输入LR模型,这两步是独立训练的,所以不需要把LR的梯度回传到GBDT。
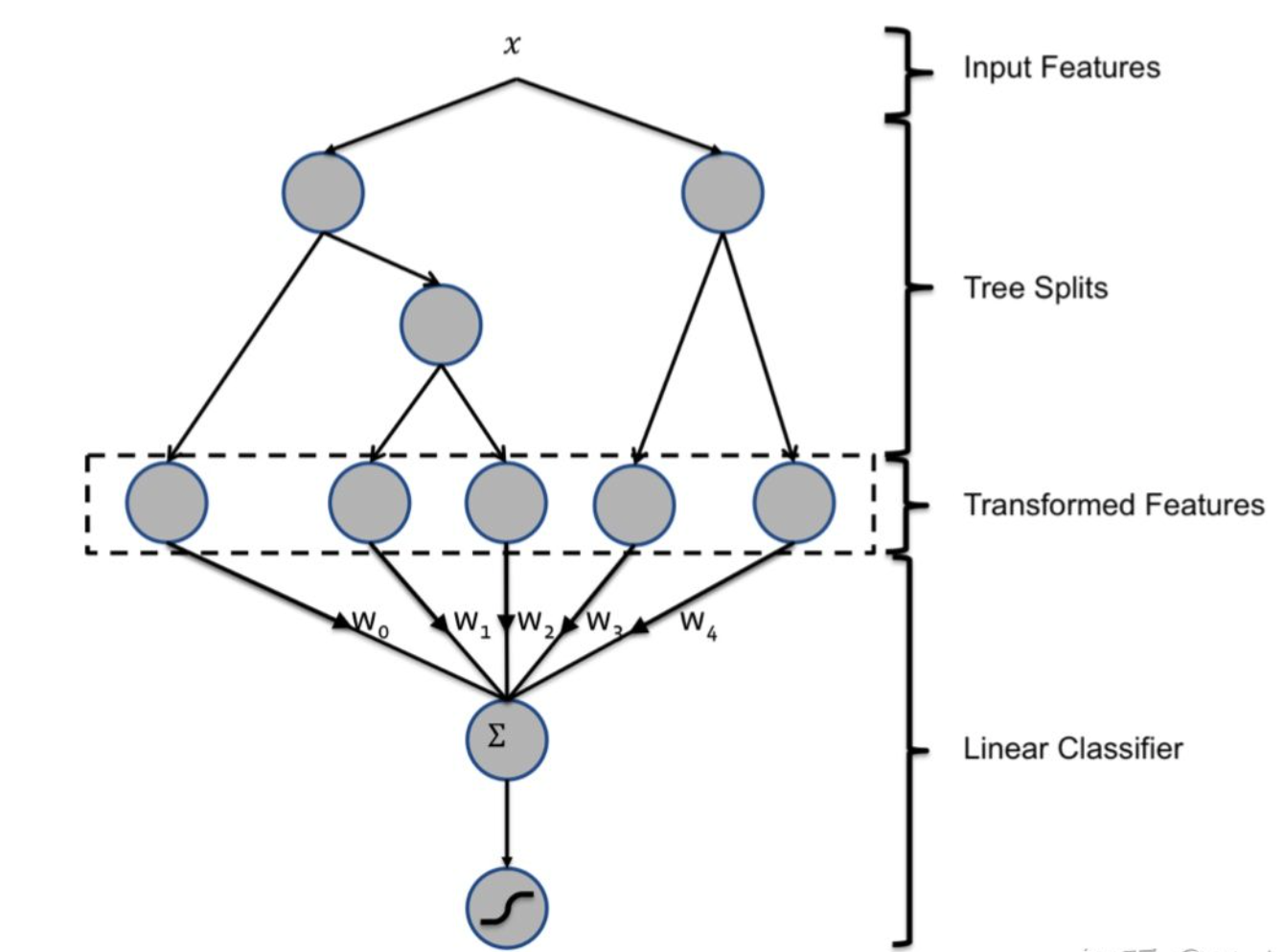
2. GBDT是什么
基本结构:决策树组成的树林,通过逐一生成决策子树生成整个树林。
生成新子树过程:利用样本标签值与当前树林预测值之间的残差。
学习方式:梯度提升。
预测方式:把所有子树结果加起来。
理论上,若可以无限生成决策树,则GBDT可以无限逼近目标拟合函数,从而达到减小预测误差的目的。
3. GBDT的特征转换过程
GBDT模型训练好之后,输入一个样本,根据每个节点的规则最终落入某一叶子节点,则该节点置为1,其他叶子节点置为0。所有叶子节点组成的向量即形成了该棵树的特征向量。把GBDT所有子树的特征向量连接起来,即形成了该样本的离散型特征向量。
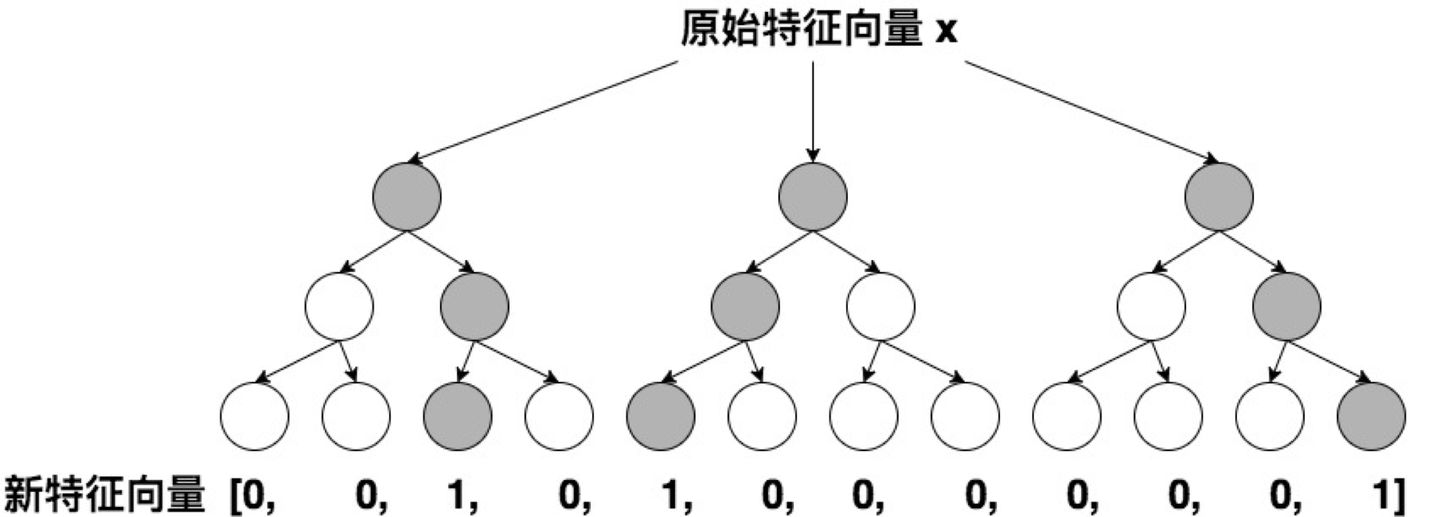
以上图为例,若输入一个样本,分别落在了三颗子树的3,1,4叶节点,则最终的样本特征向量是:[0,0,1,0, 1,0,0,0, 0,0,0,1]。
4. 特点总结
(1)决策树的深度决定了特征交叉的阶数,比FM具有更强的特征交叉能力。
(2)GBDT容易产生过拟合,且容易丢失特征的数值信息。
(3)因此特征交叉能力强不意味着效果就一定会好。
(4)组合模型的提出意味着特征工程可以完全交由一个独立的模型来完成,模型的输入是原始的特征向量,不需要投入过多人工筛选和模型设计的精力,真正的实现端到端训练。
6. 大规模分段线性模型(LS-PLM)
1. 简介
LS-PLM(Large Scale Piece-wise Linear Model),早在2012年就成为了阿里巴巴主流的推荐模型,主要应用于各类广告推荐场景,在2017年公之于众。
2. 模型结构
LS-PLM,结构与三层神经网络相似,在LR的基础上采用分而治之的思想,先对样本进行聚类分类,再对分类的样本使用LR进行CTR预估。因此本质上可以看成是对LR的推广,所以又被称为MLR(Mixed Logistic Regression,混合逻辑回归)模型。比如女装广告的CTR预估不希望把男性用户点击数码类产品的样本数据纳入训练集。
3. 原理
LS-PLM的数学形式如下:
$$
f(x) = \sum^{m}{i=1} \pi{i}(x) \cdot \eta_{i}(x) = \sum^{m}{i=1}{\frac{e^{\mu_i \cdot x}}{\sum^{m}{j=1} e^{\mu_j \cdot x}} \cdot \frac{1}{1 + e^{-w_j \cdot x}}}
$$
其中$\pi$为聚类函数,采用了$softmax$函数对样本进行多分类。$m$为超参数,表示分类数,可以较好的平衡模型的拟合与推广能力。当$m=1$时,LS-PLM退化为LR。$m$越大,表示能力越精确,拟合能力越强,但是参数量越大。
在每个分类内部构件LR模型,将每个样本的各个分类概率与LR的得分进行加权平均,得到最终的预估值。
4. 模型优点
(1)端到端的非线性学习能力。LS-PLM的分类能力使得模型可以提取样本中的非线性特征,省去了大量的人工样本处理和特征工程的过程,可以完成端到端的训练。
(2)模型的稀疏性强。LS-PLM建模时引入了L1和L2范数,使得最终训练完的模型具有较高的稀疏性,因此部署时更加轻量级。
参考资料
《深度学习推荐系统实战》 — 极客时间,王喆
《深度学习推荐系统》 — 王喆
本文永久更新地址: https://notlate.cn/p/41c5f3f519249ded/
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?