1. 高并发线上服务
1. 工业级推荐服务器功能
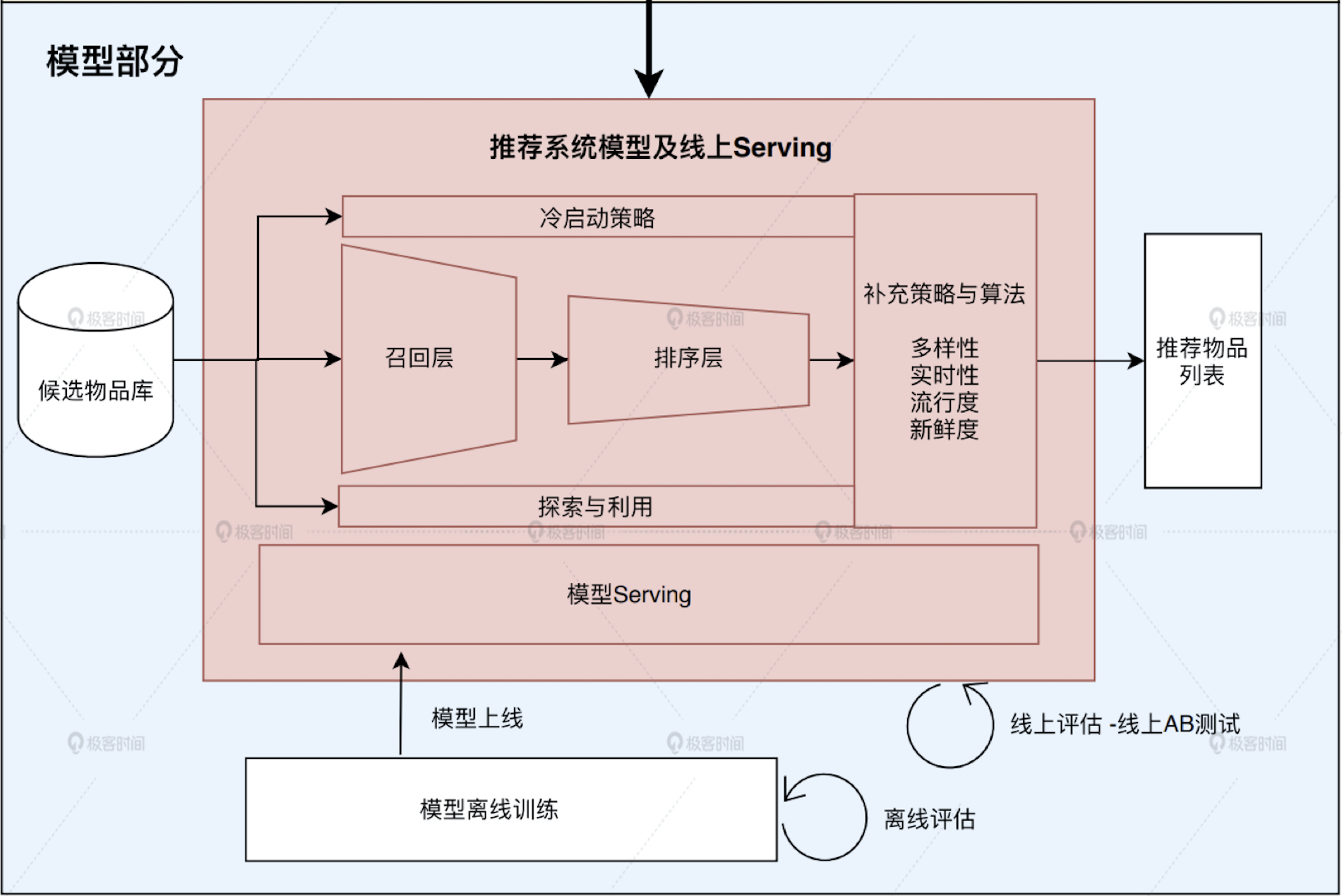
- 需要跟离线训练好的模型打交道,把离线模型进行上线,在线进行模型服务(Model Serving),
- 需要跟数据库打交道,把候选物品和离线处理好的特征载入到服务器
- 召回层、排序层、业务逻辑(结果多样性、流行度)
- AB 测试
2. 高并发推荐服务整体架构
-
负载均衡:nginx或专门的硬件级负载均衡设备
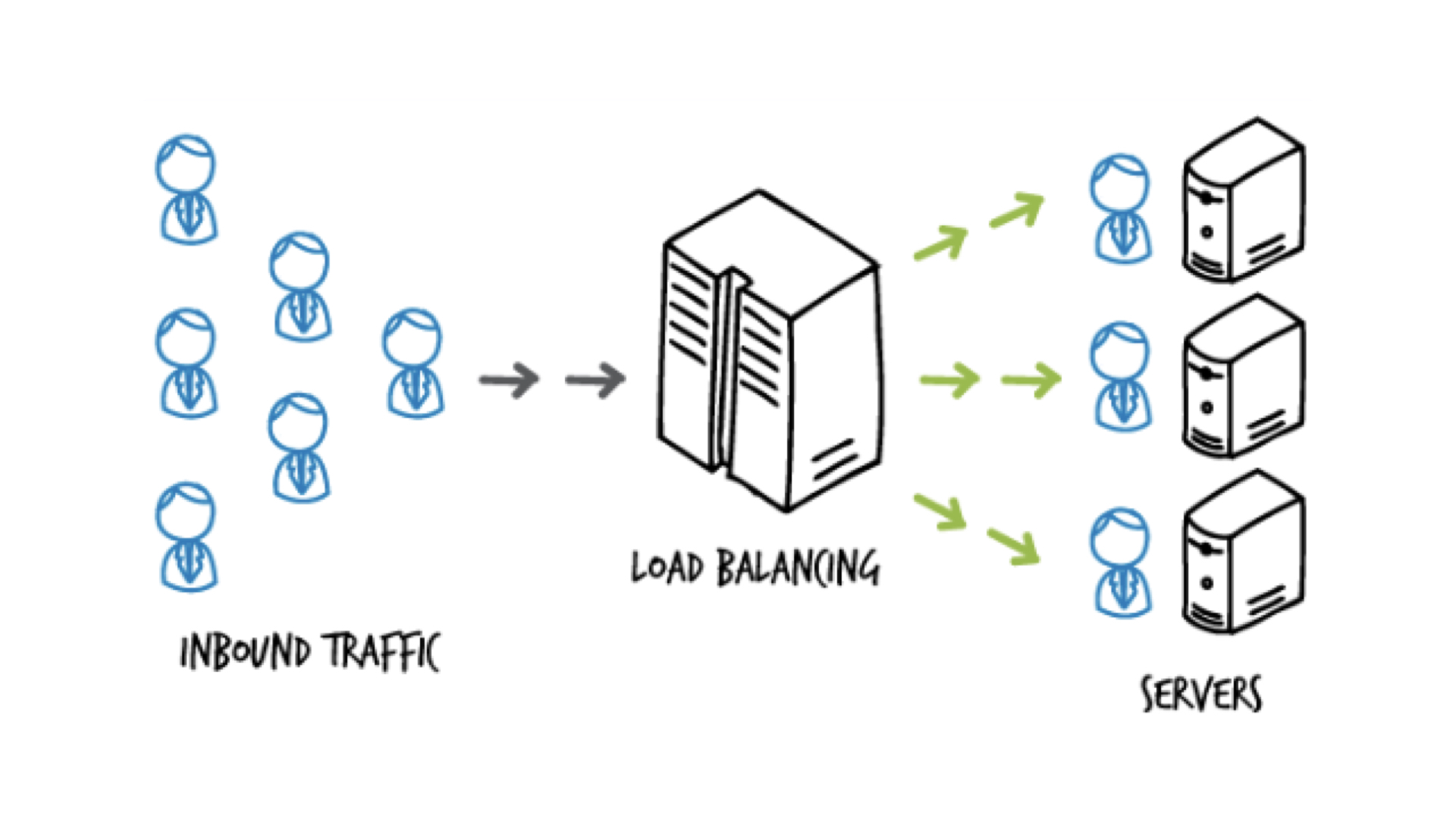
负载均衡策略:
- 如果硬件配置基本一样且部署服务一样,就采用轮询或者随机的负载均衡策略
- 如果硬件配置不同,可以根据硬件的计算能力做加权的负载均衡策略
- 同样也可以利用源地址hash做策略
-
关于扩容和缩容:可以根据系统负载情况做动态调整
-
缓存
(1) 预先缓存好几类新用户的推荐列表
(2) 利用新用户有限的信息,比如ip,注册信息等做一个简单的聚类,为每个人群聚类产生合适的推荐列表提前缓存
(3) 缓存有TTL过期时间
-
推荐服务降级机制
(1) 抛弃原本的复杂逻辑,采用最保险、最简单、最不消耗资源的降级服务来渡过特殊时期
(2) 要有成熟的监控系统
2. 推荐特征存储
-
存储模块设计原则:分级存储,把越频繁访问的数据放到越快的数据库甚至缓存中,把海量的全量数据放到廉价但是查询速度较慢的数据库中。
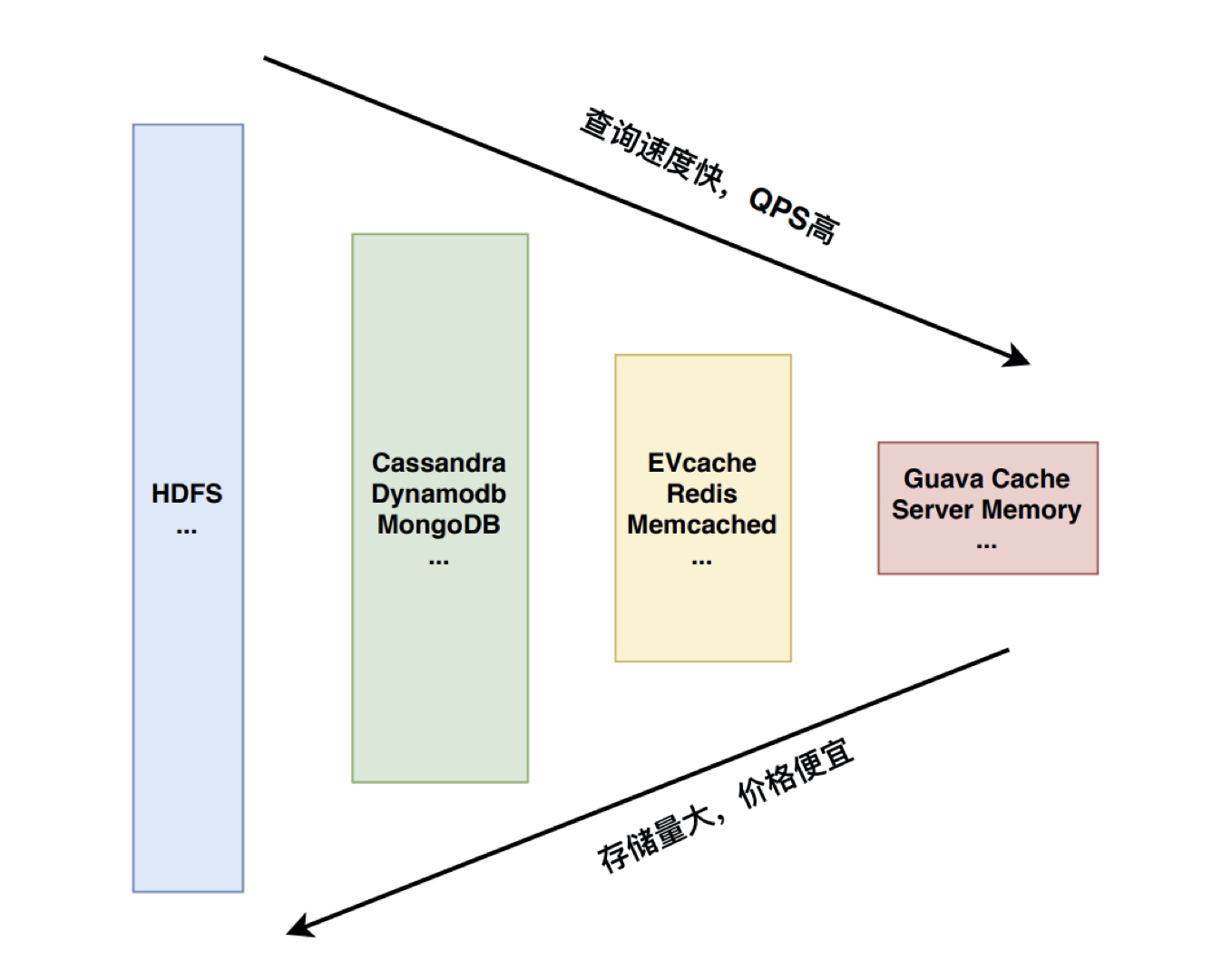
-
存储示例:
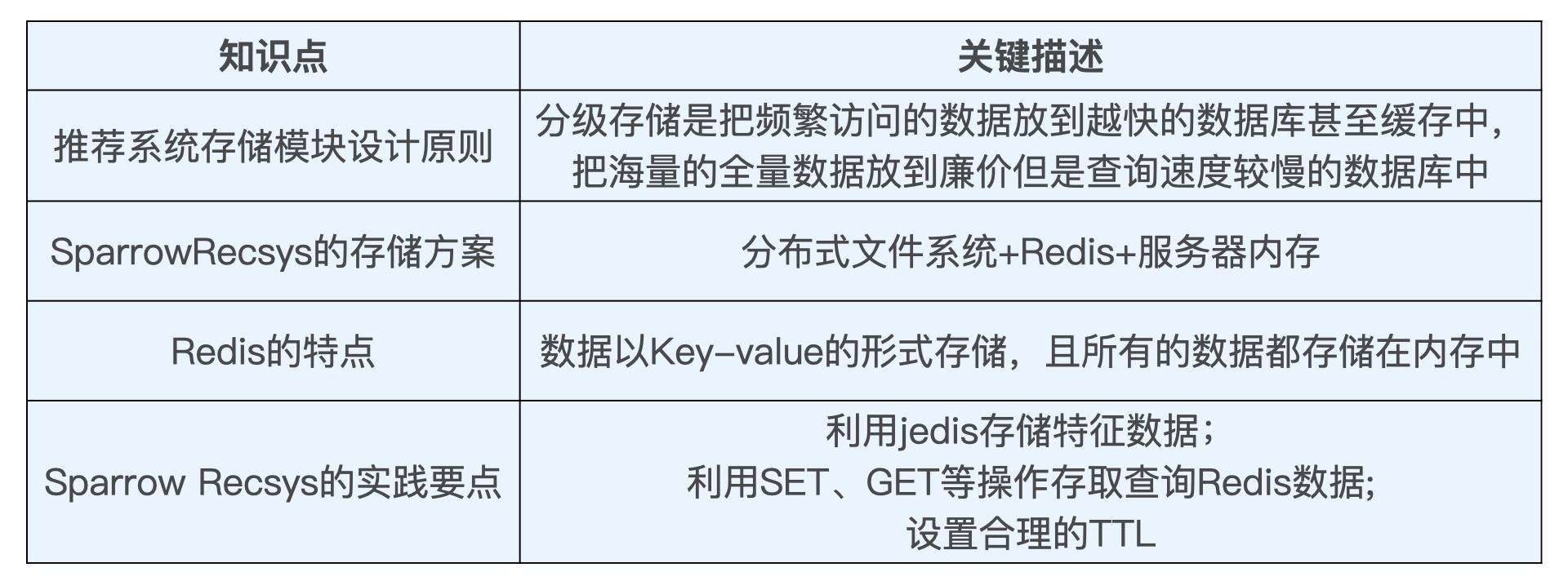
-
Redis使用经验:
(1)redis keys命令不能用在生产环境中,如果数量过大效率十分低,导致redis长时间堵塞在keys上。生产环境我们一般选择提前载入一些warm up物品id的方式载入物品embedding
(2)Redis value 可以用protobuf格式存储, 存储上节省空间. 解析起来相比string, cpu的效率也应该会更高
(3)把item embedding提前加载到内存里
(4)关于user embedding,指定一个内存区域的大小,用FIFO的方案来缓存,这样内存用完了,就自动把早进来的用户pop出去
(5)如果有条件可以判断活跃用户,可以尽量选择活跃用户进行缓存
3. 召回层
1. 作用
快速又准确地筛选掉不相关物品,从而节约排序时所消耗的计算资源。
2. 与排序层的比较
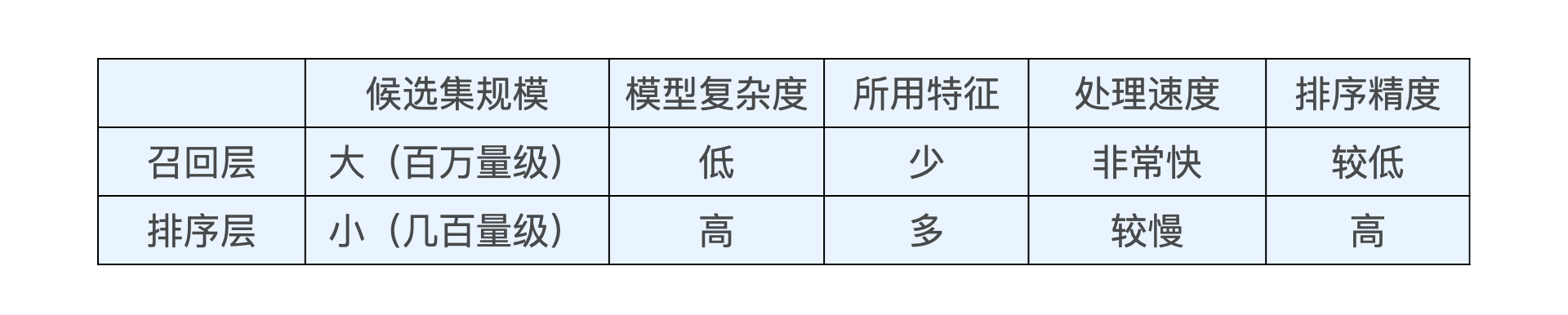
3. 指标
- 计算速度
- 召回率
4. 技术
-
单策略召回
(1)概念:通过制定一条规则或者利用一个简单模型来快速地召回可能的相关物品。规则其实就是用户可能感兴趣的物品的特点。
(2)优点:简单直观,计算速度非常快
(3)缺点:局限性很大
-
多路召回
(1)概念:采用不同的策略、特征或简单模型,分别召回一部分候选集,然后把候选集混合在一起供后续排序模型使用的策略
(2)优点:平衡计算速度与召回率
(3)缺点:在确定每一路的召回物品数量时,往往需要大量的人工参与和调整,具体的数值需要经过大量线上 AB 测试来决定。同时,策略之间的信息和数据是割裂的,所以我们很难综合考虑不同策略对一个物品的影响
-
基于Embedding的召回
(1)概念:利用物品和用户 Embedding 相似性来构建召回层
(2)优点:
-
多路召回中使用的“兴趣标签”“热门度”“流行趋势”“物品属性”等信息都可以作为 Embedding 方法中的附加信息(Side Information),融合进最终的 Embedding 向量中,相当于考虑到了多路召回的多种策略。
-
Embedding 召回的评分具有连续性,可以把 相似度作为唯一的判断标准,因此它可以随意限定召回的候选集大小。
-
在线上服务的过程中,Embedding 相似性的计算也相对简单和直接。通过简单的点积或余弦相似度的运算就能够得到相似度得分,便于线上的快速召回。
-
横向比较三种技术
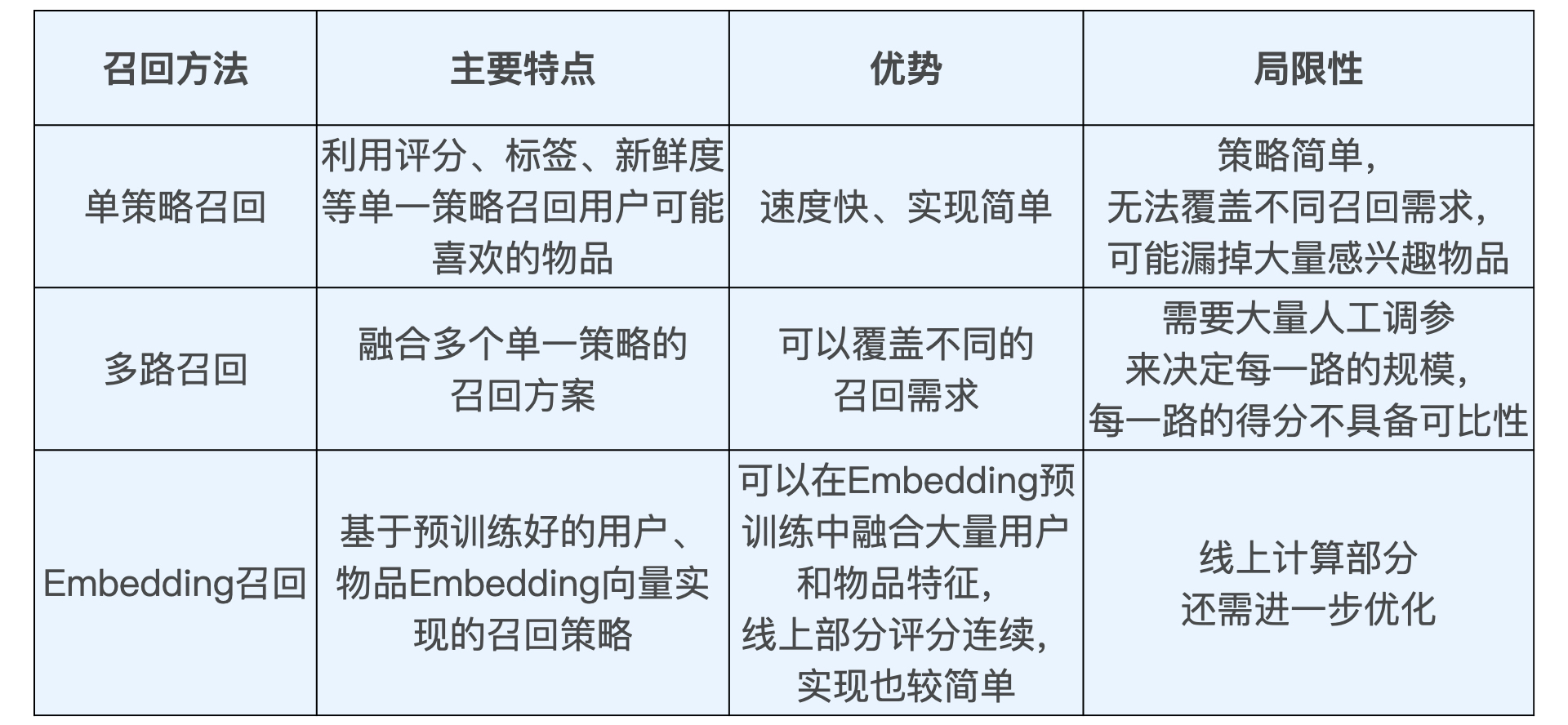
5. 召回层经典问答
-
电商领域商品维度非常大,EGES训练过慢,怎么办?
EGES 指的是阿里提出的一种 Graph Embedidng 方法,全称是 Enhanced Graph Embedding with Side Information,补充信息增强图 Embedding。它是一种融合了经典的 Deep Walk Graph Embedding 结果和其他特征的 Embedding 方法,具体步骤如下:
(1)把商品embedding进行预训练,再跟其他side information特征一起输入EGES。
(2)hash方法
(3)商品的聚类后输入,比如非常类似的商品,可以用一个商品id替代,当作一个商品来处理。这个方法airbnb embedding的论文讲的非常好。
-
用户Embedding怎么计算的?
最简单的user embedding生成方法。之前我们说过embedding之间是可以进行运算的。所以用用户喜欢的物品的embedding平均去代表这个用户是非常直观且实用
-
多路召回中,topk除了根据经验值确定,业界通用的是怎么确定k得大小呢?
在系统延迟允许的情况下,其实k取的越大越好。一般来说,如果最后的推荐结果需要n条,k取5-10n是比较合适的。
-
如果基于兴趣标签做召回,同一个物品有多个标签,用户也计算出了多个兴趣标签,如何做用户的多兴趣标签与物品的最优匹配呢?若物品标签有多层,怎么利用上一层的标签呢?
(1)简单做法:把兴趣标签转成MultiHot向量,然后计算用户和物品的相似度。
(2)复杂一点:计算每个兴趣标签的TF-IDF,为标签分配权重后,再转成MultiHot向量。
(3)若标签有多层,不妨把多层标签全部放到MultiHot向量中,高层标签的权重可以适当降低。
4. 局部敏感哈希(LSH)
1. 思想
召回与用户向量最相似的物品 Embedding 向量这一问题,其实就是在向量空间内搜索最近邻的过程。
2. 如何搜索最近邻?
-
聚类
(1)常见方法:K-means等
(2)存在的问题:
-
聚类边缘的点的最近邻往往会包括相邻聚类的点,如果我们只在类别内搜索,就会遗漏这些近似点
-
中心点的数量 k 也不那么好确定,k 选得太大,离线迭代的过程就会非常慢,k 选得太小,在线搜索的范围还是很大,并没有减少太多搜索时间
-
索引
(1)实现方法:向量空间索引方法 Kd-tree(K-dimension tree)
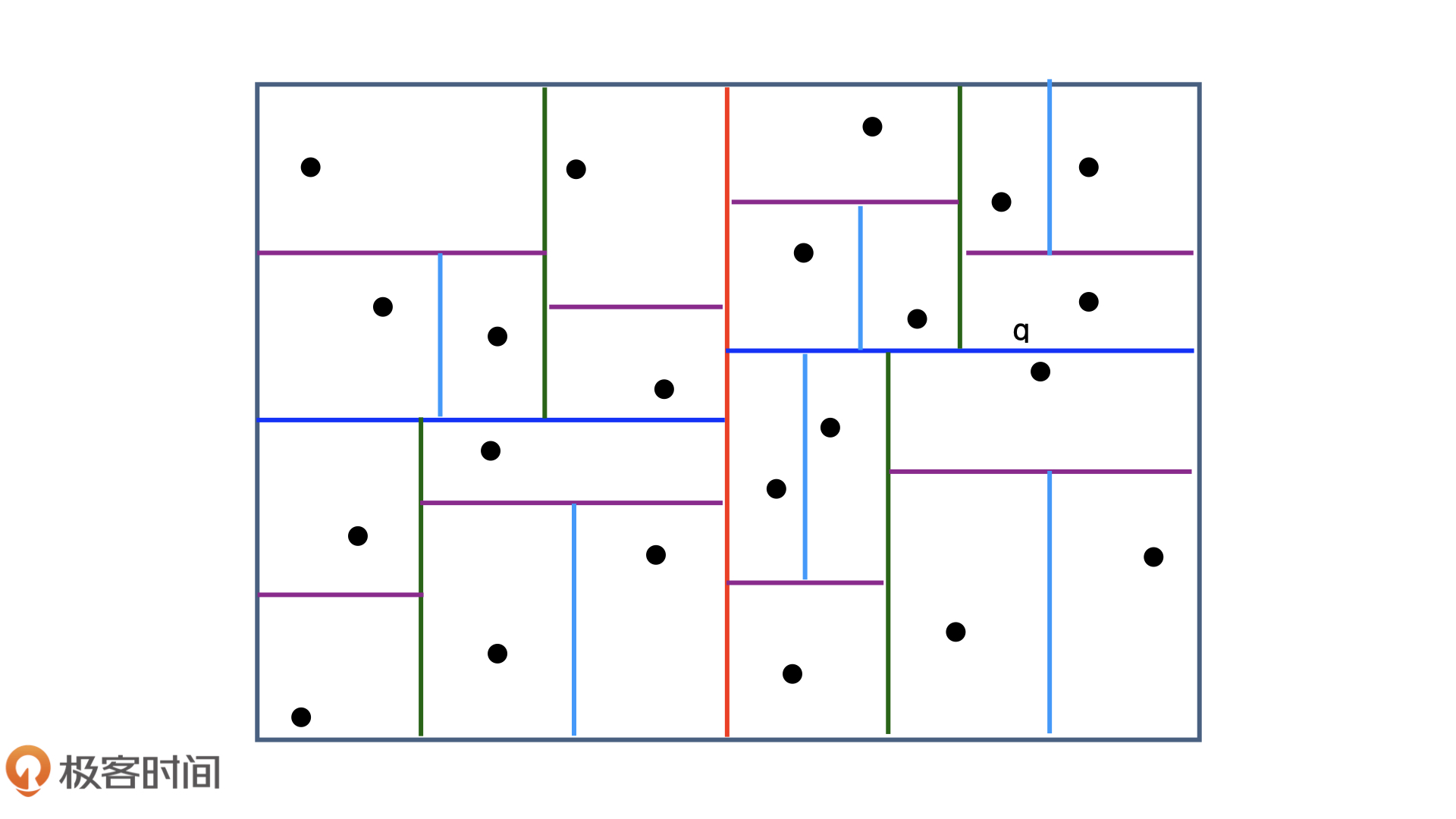
先用红色的线把点云一分为二,再用深蓝色的线把各自片区的点云一分为二,以此类推,直到每个片区只剩下一个点,这就完成了空间索引的构建。
(2)存在的问题:
- 会遗漏掉最近邻点,它只能保证快速搜索到近似的最近邻点集合
-
Kd-tree 索引的结构并不简单,离线和在线维护的过程也相对复杂,这些都是它的弊端
-
局部敏感哈希和多桶
(1)基本思想:希望让相邻的点落入同一个“桶”,这样在进行最近邻搜索时,我们仅需要在一个桶内,或相邻几个桶内的元素中进行搜索即可
(2)定性结论:欧式空间中,将高维空间的点映射到低维空间,原本接近的点在低维空间中肯定依然接近,但原本远离的点则有一定概率变成接近的点
(3)构建单桶:
* 假设$v$是高维空间中的$k$维 Embedding 向量,$x$是随机生成的 $k$ 维映射向量。那我们*利用内积操作可以将$ v $映射到一维空间,得到数值 $h(v)=v⋅x$。
* 使用哈希函数$ h(v) $进行分桶,公式为:$h^{x,b}(v)=⌊\frac{x⋅v+b}{w}⌋$,$w$ 是分桶宽度,$b$是$ 0 $到$ w $间的一个均匀分布随机变量,避免分桶边界固化。$x$和$b$的改变会生成不同的哈希函数$ h(v) $。
* 随机调整b,生成多个hash函数,并且采用或的方式组合,就可以一定程度避免这些边界点的问题
(4)构建多桶:采用 m 个哈希函数同时进行分桶,如果两个点同时掉进了 m 个桶,那它们是相似点的概率将大大增加。
(5)如何处理多桶关系:
* 且(And)操作:最大程度地减少候选点数量,也增大了漏掉最近邻点的概率。
* 或(Or)操作:减少了漏掉最近邻点的可能性,也增大了后续计算的开销。
(6)多桶策略实际建议:
* 点数越多,我们越应该增加每个分桶函数中桶的个数;相反,点数越少,我们越应该减少桶的个数;
* Embedding 向量的维度越大,我们越应该增加哈希函数的数量,尽量采用且的方式作为多桶策略;相反,Embedding 向量维度越小,我们越应该减少哈希函数的数量,多采用或的方式作为分桶策略。
-
向量最近邻搜索库 FAISS,可以替代LSH
5. 模型服务
1. 业界主流模型服务方法
-
预存推荐结果或 Embedding 结果
(1)原理:在离线环境下生成对每个用户的推荐结果,然后将结果预存到以 Redis 为代表的线上数据库中。这样,我们在线上环境直接取出预存数据推荐给用户即可。
(2)优缺点:

(3)适用场景:用户规模较小,或者一些冷启动、热门榜单等特殊的应用场景中。
-
预训练 Embedding+轻量级线上模型
(1)原理:用复杂深度学习网络离线训练生成 Embedding,存入内存数据库,再在线上实现逻辑回归或浅层神经网络等轻量级模型来拟合优化目标
(2)案例:阿里的MIMN(Multi-channel user Interest Memory Network,多通道用户兴趣记忆网络)
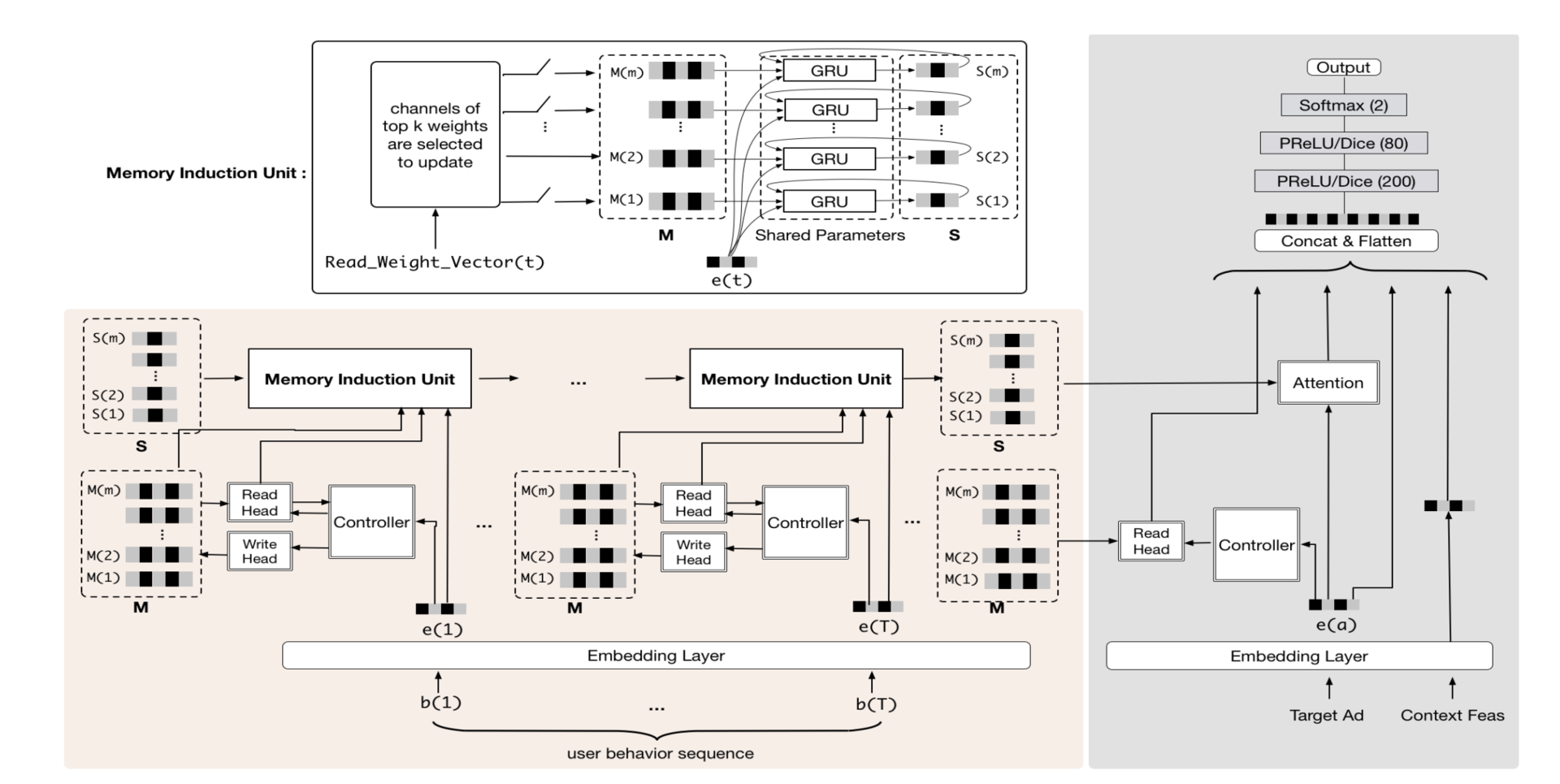
- 左边的部分不管多复杂,它们其实是在线下训练生成的,而右边的部分是一个经典的多层神经网络,它才是真正在线上服务的部分。
- S(1)-S(m) 和 M(1)-M(m)是在离线生成的 Embedding 向量,在 MIMN 模型中,它们被称为“多通道用户兴趣向量”,这些 Embedding 向量就是连接离线模型和线上模型部分的接口。
- 线上部分从 Redis 之类的模型数据库中拿到这些离线生成 Embedding 向量,然后跟其他特征的 Embedding 向量组合在一起,扔给一个标准的多层神经网络进行预估。
(3)优缺点:
- 优点:隔离了离线模型的复杂性和线上推断的效率要求。
-
缺点:割裂了模型,不是端到端训练+部署的完美方案
-
PMML 模型
(1)介绍:全称是“预测模型标记语言”(Predictive Model Markup Language, PMML),它是一种通用的以 XML 的形式表示不同模型结构参数的标记语言。在模型上线的过程中,PMML 经常作为中间媒介连接离线训练平台和线上预测平台。
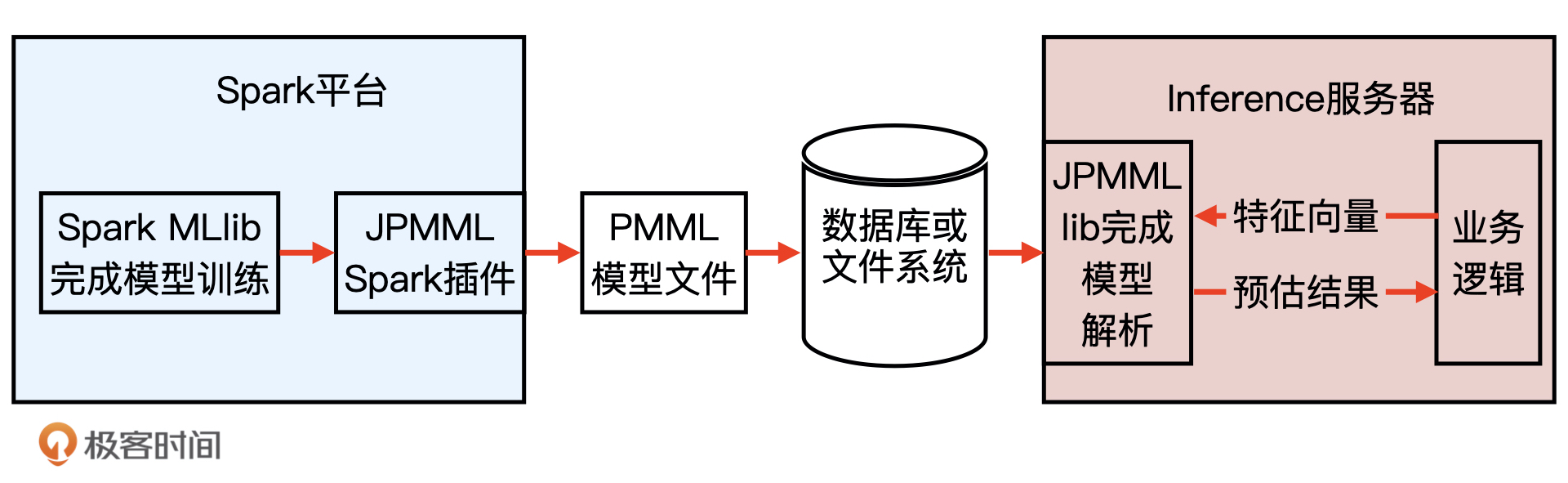
(2)优缺点:
- 优点:PMML 在 Java Server 部分只进行推断,不考虑模型训练、分布式部署等一系列问题,因此 library 比较轻,能够高效地完成推断过程。
-
缺点:对于具有复杂结构的深度学习模型来说,PMML 语言的表示能力还是比较有限的,还不足以支持复杂的深度学习模型结构。
-
TensorFlow Serving
原理:模型存储、模型载入还原以及提供服务
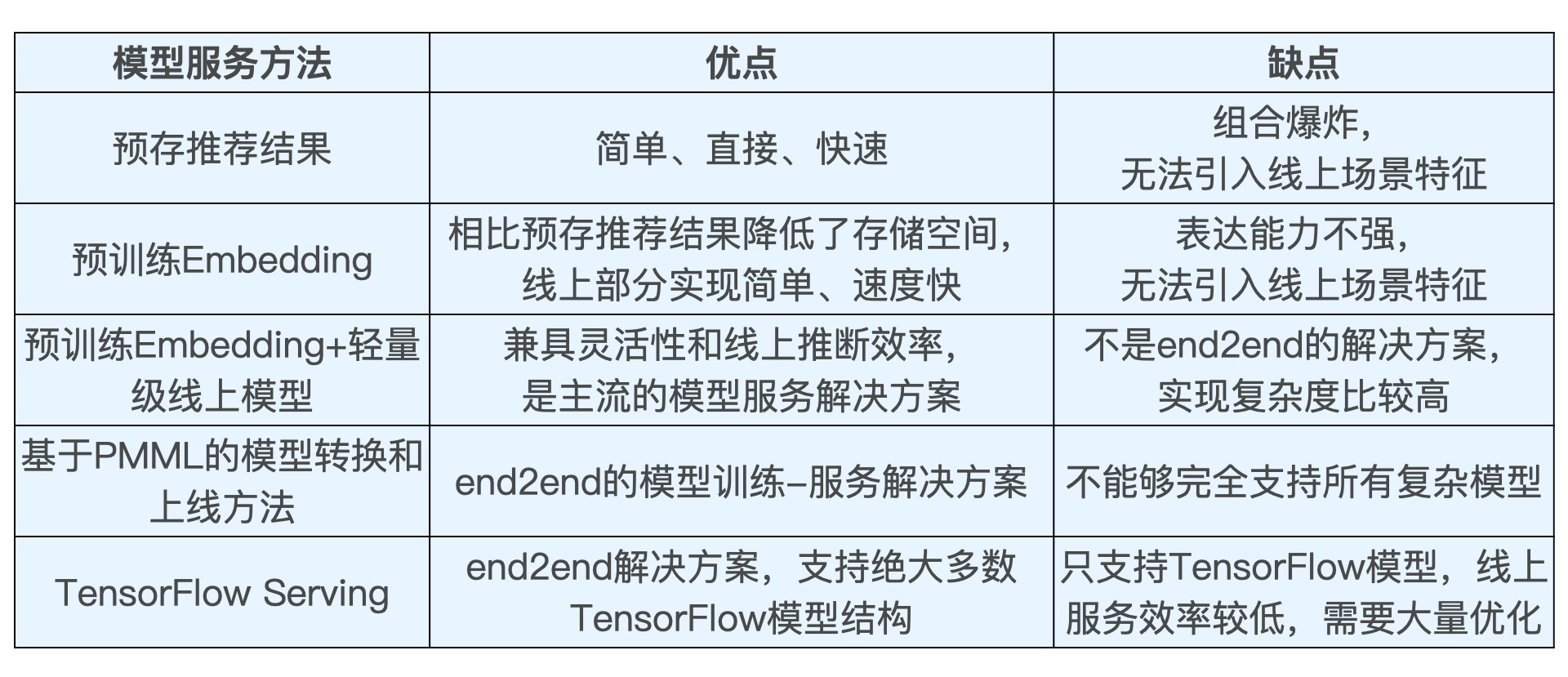
2. 几种方法横向比较
3. Embedding经验
-
Embedding层K值的选择
经验公式:K = Embedding维数开4次方,x初始的维度数,后续K的调参按照2的倍数进行调整。
参考资料
《深度学习推荐系统实战》 — 极客时间,王喆
本文永久更新地址: https://notlate.cn/p/bf49b117c97ac1ce/
Your article helped me a lot, is there any more related content? Thanks!
Your article helped me a lot, is there any more related content? Thanks!