竞价广告计算法
常用的定价策略
- 广义第二高价(GSP)
- 市场保留价(MRP)
- 价格挤压
最关键的两个计算问题
- 广告检索
- 广告排序
搜索广告系统
优化目标
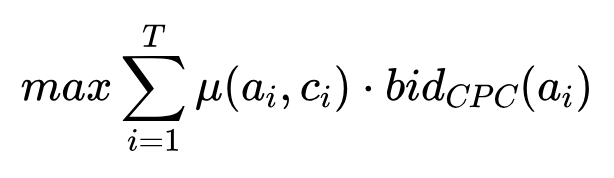
关键技术
-
查询扩展
- 意义:需求方通过扩展关键词获得更多的流量,供给方借此来变现更多流量和提高竞价的激烈程度
-
扩展方法
- 第五章介绍了精确匹配、短语匹配、广泛匹配、否定匹配,本章主要介绍广泛匹配
-
基于推荐的方法:构建会话和关键词的交互强度矩阵,可通过协同过滤(CF)方法进行推荐
-
CF具体划分
- 基于内存的非参数化方法
- 基于模型的参数化方法
-
空间降维与主题模型区别
- 推荐问题中:把未观测到的交互单元视为未知
- 主题模型中:认为未在某文档中出现的词交互强度为0
-
-
基于主题模型的方法
- 计算两个词的主题向量相似度,主要考虑的是语义上的相关性,非用户意图上的相关性,因此效果略差
-
基于历史效果的方法
- 从历史数据中发现某些关键词对某些特定广告主的eCPM较高,那么将这些查询记录下来。
- 对营收效果往往好于上两种
-
检索技术:倒排索引是搜索引擎的关键技术
- 点击率预测:14章重点介绍
- 广告放置:搜索引擎广告中确定各区放置广告条数的问题,是一个典型的带约束优化问题
广告网络
特点:除搜索广告以外最重要的非实时竞价类广告产品
优化目标
- 广告网络的成本是分成或包断媒体资源,因此成本项去掉
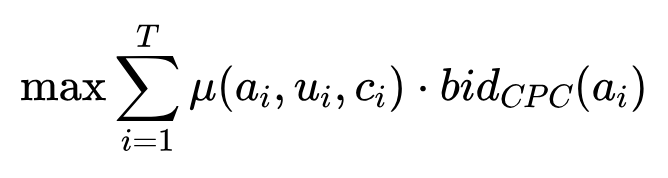
系统架构
-
广告投放的决策流程
- 服务器接收前端用户访问出发的广告请求
- 根据上下文信息和用户身份标识,从页面标签库和用户标签库查出标签
- 用这些标签以及其他广告请求条件从广告索引中找到符合要求的广告候选集
- 利用CRT预估模型计算所有候选广告的eCPM
- 根据eCPM排序选出赢得竞价的广告,返回给前端
-
离线计算流程
- 广告网络需要根据广告投放的历史展示和点击数据,对点击率进行建模
- 受众定向功能计算
-
流式计算流程
- 准实时的计费和点击反作弊功能必不可少
- 将用户行为尽快反馈到广告决策中对于点击率预估和受众定向效果提升也很关键
关键技术
- 点击率预测
- 受众定向
-
短时行为反馈与计算
- 一些需要快速对在线日志进行处理的场景,催生了计算平台
-
具体场景
- 实时反作弊:过滤爬虫流量、突发的作弊流量等
- 实时计费:将预算耗完的广告及时下线
- 短时用户标签:利用用户分钟级别的行为数据加工用户短时兴趣的标签
- 短时动态特征:CTR中的动态特征
-
流计算编程接口:Storm等
-
广告检索
-
基本的倒排索引在广告索引中遇到的新问题
- 广告的定向条件组合,可以看成是一个由与或关系连接的布尔表达式
- 在上下文关键词和用户标签比较丰富时,查询条件可能非常多
-
广告检索技术
-
布尔表达式的检索
-
表达形式:DNF
- 每个DNF都可以分解成1个或多个交集的并
- 每个交集又可以分解为1个或多个赋值集的交
-
特点
- 1.某次请求的定向标签满足某个交集(conjunction)时,一定满足包含该交集的所有广告
- 2.在交集的倒排索引中,可以通过请求标签的个数过滤掉比其数目多的交集(因为其条件更多更精准)
-
-
相关性检索:WAND算法
- 1.合理性:与最终排序使用的评价函数近似
- 2.高效性:在检索阶段实现快速评价
-
基于DNN的语义建模
- DSSM模型
- Youtube个性化推荐模型
-
线上应用DNN模型时,往往使用用户和广告的嵌入向量进行最近邻检索
-
哈希算法
-
数据无关
- 局部敏感哈希(LSH):原始数据空间中距离近的样本点比距离远的样本点在哈希后更容易碰撞
-
数据相关/学习哈希
- 语义哈希
- 深度学习哈希
-
-
向量量化算法
- 概念:对向量x做整体量化,将其映射为K个离散向量中的一个,从而压缩数据的算法
-
常见K均值算法
- 乘积量化
- 层次K均值树HKM
-
基于图的算法
-
相对于HKM的优势
- 1.检索时可以从任意节点开始访问,因此可以做高并发检索
- 2.小世界网络可以通过相对较少的长度连接使大多数节点之间的联通路径有较短的长度(能更快的找到与查询距离更近的相似数据)
-
常见算法
-
NSW
- 1.构建索引时,通过逐步插入节点去构造小世界网络,在构造网络的初始阶段建立的连接即成为相对较少的长程连接
- 2.查询索引时,从多个节点并发检索,直到检索出的top节点收敛
-
-
-
-
-
本文永久更新地址: https://notlate.cn/p/2498c52b4e9fd75b/
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Your article helped me a lot, is there any more related content? Thanks!
Your article helped me a lot, is there any more related content? Thanks!
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Your article helped me a lot, is there any more related content? Thanks!